lingvo.wikisort.org - Alphabet
The International Phonetic Alphabet (IPA) is an alphabetic system of phonetic notation based primarily on the Latin script. It was devised by the International Phonetic Association in the late 19th century as a standardized representation of speech sounds in written form.[1] The IPA is used by lexicographers, foreign language students and teachers, linguists, speech–language pathologists, singers, actors, constructed language creators, and translators.[2][3]
| International Phonetic Alphabet | |
|---|---|
 "IPA" in IPA ([aɪ pʰiː eɪ]) | |
| Script type | Alphabet
– partially featural |
Time period | since 1888 |
| Languages | Used for phonetic and phonemic transcription of any language |
| Related scripts | |
Parent systems | Palaeotype alphabet, English Phonotypic Alphabet
|

The IPA is designed to represent those qualities of speech that are part of lexical (and, to a limited extent, prosodic) sounds in oral language: phones, phonemes, intonation, and the separation of words and syllables.[1] To represent additional qualities of speech—such as tooth gnashing, lisping, and sounds made with a cleft lip and cleft palate—an extended set of symbols may be used.[2]
Segments are transcribed by one or more IPA symbols of two basic types: letters and diacritics. For example, the sound of the English letter ⟨t⟩ may be transcribed in IPA with a single letter: [t], or with a letter plus diacritics: [t̺ʰ], depending on how precise one wishes to be. Slashes are used to signal phonemic transcription; therefore, /t/ is more abstract than either [t̺ʰ] or [t] and might refer to either, depending on the context and language.[note 1]
Occasionally, letters or diacritics are added, removed, or modified by the International Phonetic Association. As of the most recent change in 2005,[4] there are 107 segmental letters, an indefinitely large number of suprasegmental letters, 44 diacritics (not counting composites), and four extra-lexical prosodic marks in the IPA. Most of these are shown in the current IPA chart, posted below in this article and at the website of the IPA.[5]
History
In 1886, a group of French and British language teachers, led by the French linguist Paul Passy, formed what would be known from 1897 onwards as the International Phonetic Association (in French, l'Association phonétique internationale).[6] Their original alphabet was based on a spelling reform for English known as the Romic alphabet, but to make it usable for other languages the values of the symbols were allowed to vary from language to language.[note 2] For example, the sound [ʃ] (the sh in shoe) was originally represented with the letter ⟨c⟩ in English, but with the digraph ⟨ch⟩ in French.[6] In 1888, the alphabet was revised to be uniform across languages, thus providing the base for all future revisions.[6][7] The idea of making the IPA was first suggested by Otto Jespersen in a letter to Paul Passy. It was developed by Alexander John Ellis, Henry Sweet, Daniel Jones, and Passy.[8]
Since its creation, the IPA has undergone a number of revisions. After revisions and expansions from the 1890s to the 1940s, the IPA remained primarily unchanged until the Kiel Convention in 1989. A minor revision took place in 1993 with the addition of four letters for mid central vowels[2] and the removal of letters for voiceless implosives.[9] The alphabet was last revised in May 2005 with the addition of a letter for a labiodental flap.[10] Apart from the addition and removal of symbols, changes to the IPA have consisted largely of renaming symbols and categories and in modifying typefaces.[2]
Extensions to the International Phonetic Alphabet for speech pathology (extIPA) were created in 1990 and were officially adopted by the International Clinical Phonetics and Linguistics Association in 1994.[11]
Description
The general principle of the IPA is to provide one letter for each distinctive sound (speech segment).[note 3] This means that:
- It does not normally use combinations of letters to represent single sounds, the way English does with ⟨sh⟩, ⟨th⟩ and ⟨ng⟩, or single letters to represent multiple sounds, the way ⟨x⟩ represents /ks/ or /ɡz/ in English.
- There are no letters that have context-dependent sound values, the way ⟨c⟩ and ⟨g⟩ in several European languages have a "hard" or "soft" pronunciation.
- The IPA does not usually have separate letters for two sounds if no known language makes a distinction between them, a property known as "selectiveness".[2][note 4] However, if a large number of phonemically distinct letters can be derived with a diacritic, that may be used instead.[note 5]
The alphabet is designed for transcribing sounds (phones), not phonemes, though it is used for phonemic transcription as well. A few letters that did not indicate specific sounds have been retired (⟨ˇ⟩, once used for the "compound" tone of Swedish and Norwegian, and ⟨ƞ⟩, once used for the moraic nasal of Japanese), though one remains: ⟨ɧ⟩, used for the sj-sound of Swedish. When the IPA is used for phonemic transcription, the letter–sound correspondence can be rather loose. For example, ⟨c⟩ and ⟨ɟ⟩ are used in the IPA Handbook for /t͡ʃ/ and /d͡ʒ/.
Among the symbols of the IPA, 107 letters represent consonants and vowels, 31 diacritics are used to modify these, and 17 additional signs indicate suprasegmental qualities such as length, tone, stress, and intonation.[note 6] These are organized into a chart; the chart displayed here is the official chart as posted at the website of the IPA.
Letter forms

The letters chosen for the IPA are meant to harmonize with the Latin alphabet.[note 7] For this reason, most letters are either Latin or Greek, or modifications thereof. Some letters are neither: for example, the letter denoting the glottal stop, ⟨ʔ⟩, originally had the form of a dotless question mark, and derives from an apostrophe. A few letters, such as that of the voiced pharyngeal fricative, ⟨ʕ⟩, were inspired by other writing systems (in this case, the Arabic letter ⟨ﻉ⟩, ʿayn, via the reversed apostrophe).[9]
Some letter forms derive from existing letters:
- The right-swinging tail, as in ⟨ʈ ɖ ɳ ɽ ʂ ʐ ɻ ɭ ⟩, indicates retroflex articulation. It originates from the hook of an r.
- The top hook, as in ⟨ɠ ɗ ɓ⟩, indicates implosion.
- Several nasal consonants are based on the form ⟨n⟩: ⟨n ɲ ɳ ŋ⟩. ⟨ɲ⟩ and ⟨ŋ⟩ derive from ligatures of gn and ng, and ⟨ɱ⟩ is an ad hoc imitation of ⟨ŋ⟩.
- Letters turned 180 degrees, such as ⟨ɐ ɔ ə ɟ ɓ ɥ ɾ ɯ ɹ ʇ ʊ ʌ ʍ ʎ⟩ (from ⟨a c e f ɡ h ᴊ m r t Ω v w y⟩),[note 8] when either the original letter (e.g., ⟨ɐ ə ɹ ʇ ʍ⟩) or the turned one (e.g., ⟨ɔ ɟ ɓ ɥ ɾ ɯ ʌ ʎ⟩) is reminiscent of the target sound. This was easily done in the era of mechanical typesetting, and had the advantage of not requiring the casting of special type for IPA symbols, much as the same sorts had traditionally often been used for ⟨b⟩ and ⟨q⟩, ⟨d⟩ and ⟨p⟩, ⟨n⟩ and ⟨u⟩, ⟨6⟩ and ⟨9⟩ to reduce cost.

An example of a font that uses turned small-capital omega, ⟨ꭥ⟩, for the vowel ⟨ʊ⟩. The symbol had originally been a small-capital ⟨ᴜ⟩.
- Among consonant letters, the small capital letters ⟨ɢ ʜ ʟ ɴ ʀ ʁ⟩, and also ⟨ꞯ⟩ in extIPA, indicate more guttural sounds than their base letters. (⟨ʙ⟩ is a late exception.) Among vowel letters, small capitals indicate "lax" vowels. Most of the original small-cap vowel letters have been modified into more distinctive shapes (e.g. ⟨ʊ ɤ ɛ ʌ⟩), with only ⟨ɪ ʏ⟩ remaining as small capitals.

Typography and iconicity
The International Phonetic Alphabet is based on the Latin script, and uses as few non-Latin letters as possible.[6] The Association created the IPA so that the sound values of most letters letters would correspond to "international usage" (approximately Classical Latin).[6] Hence, the consonant letters ⟨b⟩, ⟨d⟩, ⟨f⟩, (hard) ⟨ɡ⟩, (non-silent) ⟨h⟩, (unaspirated) ⟨k⟩, ⟨l⟩, ⟨m⟩, ⟨n⟩, (unaspirated) ⟨p⟩, (voiceless) ⟨s⟩, (unaspirated) ⟨t⟩, ⟨v⟩, ⟨w⟩, and ⟨z⟩ have more or less the values found in English; and the vowel letters ⟨a⟩, ⟨e⟩, ⟨i⟩, ⟨o⟩, ⟨u⟩ correspond to the (long) sound values of Latin: [i] is like the vowel in machine, [u] is as in rule, etc. Other Latin letters, particularly ⟨j⟩, ⟨r⟩ and ⟨y⟩, differ from English, but have their IPA values in Latin or other European languages.
This basic Latin inventory was extended by adding small-capital and cursive forms, diacritics and rotation. The sound values of these letters are related to those of the original letters, and their derivation may be iconic.[12] For example, letters with a rightward-facing hook at the bottom represent retroflex equivalents of the source letters, and small capital letters usually represent uvular equivalents of their source letters.
There are also several letters from the Greek alphabet, though their sound values may differ from Greek. The most extreme difference is ⟨ʋ⟩, which is a vowel in Greek but a consonant in the IPA. For most Greek letters, subtly different glyph shapes have been devised for the IPA, specifically ⟨ɑ⟩, ⟨ꞵ⟩, ⟨ɣ⟩, ⟨ɛ⟩, ⟨ɸ⟩, ⟨ꭓ⟩ and ⟨ʋ⟩, which are encoded in Unicode separately from their parent Greek letters. One, however – ⟨θ⟩ – has only its Greek form, while for ⟨ꞵ ~ β⟩ and ⟨ꭓ ~ χ⟩, both Greek and Latin forms are in common use.[13] The tone letters are not derived from an alphabet, but from a pitch trace on a musical scale.
Beyond the letters themselves, there are a variety of secondary symbols which aid in transcription. Diacritic marks can be combined with IPA letters to add phonetic detail such as tone and secondary articulations. There are also special symbols for prosodic features such as stress and intonation.
Brackets and transcription delimiters
There are two principal types of brackets used to set off (delimit) IPA transcriptions:
| Symbol | Use |
|---|---|
| [ ... ] | Square brackets are used with phonetic notation, whether broad or narrow[14] – that is, for actual pronunciation, possibly including details of the pronunciation that may not be used for distinguishing words in the language being transcribed, which the author nonetheless wishes to document. Such phonetic notation is the primary function of the IPA. |
| / ... / | Slashes[note 9] are used for abstract phonemic notation,[14] which note only features that are distinctive in the language, without any extraneous detail. For example, while the 'p' sounds of English pin and spin are pronounced differently (and this difference would be meaningful in some languages), the difference is not meaningful in English. Thus, phonemically the words are usually analyzed as /ˈpɪn/ and /ˈspɪn/, with the same phoneme /p/. To capture the difference between them (the allophones of /p/), they can be transcribed phonetically as [pʰɪn] and [spɪn]. Phonemic notation commonly uses IPA symbols that are rather close to the default pronunciation of a phoneme, but for legibility or other reasons can use symbols that diverge from their designated values, such as /c, ɟ/ for affricates typically pronounced [t͜ʃ, d͜ʒ], as found in the Handbook, or /r/, which in phonetic notation is a trill, for English r even when pronounced [ɹʷ]. |
Other conventions are less commonly seen:
| Symbol | Use |
|---|---|
| { ... } | Braces ("curly brackets") are used for prosodic notation.[15] See Extensions to the International Phonetic Alphabet for examples in this system. |
| ( ... ) | Parentheses are used for indistinguishable[14] or unidentified utterances. They are also seen for silent articulation (mouthing),[16] where the expected phonetic transcription is derived from lip-reading, and with periods to indicate silent pauses, for example (…) or (2 sec). The latter usage is made official in the extIPA, with unidentified segments circled.[17] |
| ⸨ ... ⸩ | Double parentheses indicate either a transcription of obscured speech or a description of the obscuring noise. The IPA specifies that they mark the obscured sound,[15] as in ⸨2σ⸩, two audible syllables obscured by another sound. The current extIPA specifications prescribe double parentheses for the extraneous noise, such as ⸨cough⸩ or ⸨knock⸩ for a knock on a door, but the IPA Handbook identifies IPA and extIPA usage as equivalent.[18] Early publications of the extIPA explain double parentheses as marking "uncertainty because of noise which obscures the recording," and that within them "may be indicated as much detail as the transcriber can detect."[19] |
All three of the above are provided by the IPA Handbook. The following are not, but may be seen in IPA transcription or in associated material (especially angle brackets):
| Symbol | Use |
|---|---|
| ⟦ ... ⟧ | Double square brackets are used for extra-precise (especially narrow) transcription. This is consistent with the IPA convention of doubling a symbol to indicate greater degree. Double brackets may indicate that a letter has its cardinal IPA value. For example, ⟦a⟧ is an open front vowel, rather than the perhaps slightly different value (such as open central) that "[a]" may be used to transcribe in a particular language. Thus, two vowels transcribed for easy legibility as ⟨[e]⟩ and ⟨[ɛ]⟩ may be clarified as actually being ⟦e̝⟧ and ⟦e⟧; ⟨[ð]⟩ may be more precisely ⟦ð̠̞ˠ⟧.[20] Double brackets may also be used for a specific token or speaker; for example, the pronunciation of a child as opposed to the adult phonetic pronunciation that is their target.[21] |
| ⫽ ... ⫽ | ... | ‖ ... ‖ { ... } | Double slashes are used for morphophonemic transcription. This is also consistent with the IPA convention of doubling a symbol to indicate greater degree (in this case, more abstract than phonemic transcription).
Other symbols sometimes seen for morphophonemic transcription are pipes and double pipes, from Americanist phonetic notation; and braces from set theory, especially when enclosing the set of phonemes that constitute the morphophoneme, e.g. {t d} or {t|d} or {/t/, /d/}. Only double slashes are unambiguous: both pipes and braces conflict with IPA prosodic transcription.[note 10] See morphophonology for examples. |
| ⟨ ... ⟩ ⟪ ... ⟫ | Angle brackets[note 11] are used to mark both original Latin orthography and transliteration from another script; they are also used to identify individual graphemes of any script.[22][23] Within the IPA, they are used to indicate the IPA letters themselves rather than the sound values that they carry. Double angle brackets may occasionally be useful to distinguish original orthography from transliteration, or the idiosyncratic spelling of a manuscript from the normalized orthography of the language.
For example, ⟨cot⟩ would be used for the orthography of the English word cot, as opposed to its pronunciation /ˈkɒt/. Italics are usual when words are written as themselves (as with cot in the previous sentence) rather than to specifically note their orthography. However, italic markup is not evident to sight-impaired readers who rely on screen reader technology. |
Some examples of contrasting brackets in the literature:
In some English accents, the phoneme /l/, which is usually spelled as ⟨l⟩ or ⟨ll⟩, is articulated as two distinct allophones: the clear [l] occurs before vowels and the consonant /j/, whereas the dark [ɫ]/[lˠ] occurs before consonants, except /j/, and at the end of words.[24]
the alternations /f/ – /v/ in plural formation in one class of nouns, as in knife /naɪf/ – knives /naɪvz/, which can be represented morphophonemically as {naɪV} – {naɪV+z}. The morphophoneme {V} stands for the phoneme set {/f/, /v/}.[25]
[ˈf\faɪnəlz ˈhɛld ɪn (.) ⸨knock on door⸩ bɑɹsə{𝑝ˈloʊnə and ˈmədɹɪd 𝑝}] — f-finals held in Barcelona and Madrid.[26]
Cursive forms
IPA letters have cursive forms designed for use in manuscripts and when taking field notes, but the 1999 Handbook of the International Phonetic Association recommended against their use, as cursive IPA is "harder for most people to decipher."[27]
Braille representation
Several Braille adaptations of the IPA have seen use, the most recent published in 2008 and widely accepted since 2011. It does not have complete support for tone.
Modifying the IPA chart

The International Phonetic Alphabet is occasionally modified by the Association. After each modification, the Association provides an updated simplified presentation of the alphabet in the form of a chart. (See History of the IPA.) Not all aspects of the alphabet can be accommodated in a chart of the size published by the IPA. The alveolo-palatal and epiglottal consonants, for example, are not included in the consonant chart for reasons of space rather than of theory (two additional columns would be required, one between the retroflex and palatal columns and the other between the pharyngeal and glottal columns), and the lateral flap would require an additional row for that single consonant, so they are listed instead under the catchall block of "other symbols".[28] The indefinitely large number of tone letters would make a full accounting impractical even on a larger page, and only a few examples are shown, and even the tone diacritics are not complete; the reversed tone letters are not illustrated at all.
The procedure for modifying the alphabet or the chart is to propose the change in the Journal of the IPA. (See, for example, August 2008 on an open central unrounded vowel and August 2011 on central approximants.)[29] Reactions to the proposal may be published in the same or subsequent issues of the Journal (as in August 2009 on the open central vowel).[30] A formal proposal is then put to the Council of the IPA[31] – which is elected by the membership[32] – for further discussion and a formal vote.[33][34]
Nonetheless, many users of the alphabet, including the leadership of the Association itself, deviate from this norm.[note 12] The Journal of the IPA finds it acceptable to mix IPA and extIPA symbols in consonant charts in their articles. (For instance, including the extIPA letter ⟨𝼆⟩, rather than ⟨ʎ̝̊⟩, in an illustration of the IPA.)[35]
Usage
Of more than 160 IPA symbols, relatively few will be used to transcribe speech in any one language, with various levels of precision. A precise phonetic transcription, in which sounds are specified in detail, is known as a narrow transcription. A coarser transcription with less detail is called a broad transcription. Both are relative terms, and both are generally enclosed in square brackets.[1] Broad phonetic transcriptions may restrict themselves to easily heard details, or only to details that are relevant to the discussion at hand, and may differ little if at all from phonemic transcriptions, but they make no theoretical claim that all the distinctions transcribed are necessarily meaningful in the language.

For example, the English word little may be transcribed broadly as [ˈlɪtəl], approximately describing many pronunciations. A narrower transcription may focus on individual or dialectical details: [ˈɫɪɾɫ] in General American, [ˈlɪʔo] in Cockney, or [ˈɫɪːɫ] in Southern US English.
Phonemic transcriptions, which express the conceptual counterparts of spoken sounds, are usually enclosed in slashes (/ /) and tend to use simpler letters with few diacritics. The choice of IPA letters may reflect theoretical claims of how speakers conceptualize sounds as phonemes or they may be merely a convenience for typesetting. Phonemic approximations between slashes do not have absolute sound values. For instance, in English, either the vowel of pick or the vowel of peak may be transcribed as /i/, so that pick, peak would be transcribed as /ˈpik, ˈpiːk/ or as /ˈpɪk, ˈpik/; and neither is identical to the vowel of the French pique which would also be transcribed /pik/. By contrast, a narrow phonetic transcription of pick, peak, pique could be: [pʰɪk], [pʰiːk], [pikʲ].
Linguists
IPA is popular for transcription by linguists. Some American linguists, however, use a mix of IPA with Americanist phonetic notation or use some nonstandard symbols for various reasons.[36] Authors who employ such nonstandard use are encouraged to include a chart or other explanation of their choices, which is good practice in general, as linguists differ in their understanding of the exact meaning of IPA symbols and common conventions change over time.
Dictionaries
English
Many British dictionaries, including the Oxford English Dictionary and some learner's dictionaries such as the Oxford Advanced Learner's Dictionary and the Cambridge Advanced Learner's Dictionary, now use the International Phonetic Alphabet to represent the pronunciation of words.[37] However, most American (and some British) volumes use one of a variety of pronunciation respelling systems, intended to be more comfortable for readers of English and to be more acceptable across dialects, without the implication of a preferred pronunciation that the IPA might convey. For example, the respelling systems in many American dictionaries (such as Merriam-Webster) use ⟨y⟩ for IPA [ j] and ⟨sh⟩ for IPA [ ʃ ], reflecting the usual spelling of those sounds in English.[38] (In IPA, [y] represents the sound of the French ⟨u⟩, as in tu, and [sh] represents the sequence of consonants in grasshopper.)
Other languages
The IPA is also not universal among dictionaries in languages other than English. Monolingual dictionaries of languages with phonemic orthographies generally do not bother with indicating the pronunciation of most words, and tend to use respelling systems for words with unexpected pronunciations. Dictionaries produced in Israel use the IPA rarely and sometimes use the Hebrew alphabet for transcription of foreign words.[note 13] Bilingual dictionaries that translate from foreign languages into Russian usually employ the IPA, but monolingual Russian dictionaries occasionally use pronunciation respelling for foreign words.[note 14] The IPA is more common in bilingual dictionaries, but there are exceptions here too. Mass-market bilingual Czech dictionaries, for instance, tend to use the IPA only for sounds not found in Czech.[39]
Standard orthographies and case variants
IPA letters have been incorporated into the alphabets of various languages, notably via the Africa Alphabet in many sub-Saharan languages such as Hausa, Fula, Akan, Gbe languages, Manding languages, Lingala, etc. Capital case variants have been created for use in these languages. For example, Kabiyè of northern Togo has Ɖ ɖ, Ŋ ŋ, Ɣ ɣ, Ɔ ɔ, Ɛ ɛ, Ʋ ʋ. These, and others, are supported by Unicode, but appear in Latin ranges other than the IPA extensions.
In the IPA itself, however, only lower-case letters are used. The 1949 edition of the IPA handbook indicated that an asterisk ⟨*⟩ might be prefixed to indicate that a word was a proper name,[40] but this convention was not included in the 1999 Handbook, which notes the contrary use of the asterisk as a placeholder for a sound or feature that does not have a symbol.
Classical singing
The IPA has widespread use among classical singers during preparation as they are frequently required to sing in a variety of foreign languages. They are also taught by vocal coaches to perfect diction and improve tone quality and tuning.[41] Opera librettos are authoritatively transcribed in IPA, such as Nico Castel's volumes[42] and Timothy Cheek's book Singing in Czech.[43] Opera singers' ability to read IPA was used by the site Visual Thesaurus, which employed several opera singers "to make recordings for the 150,000 words and phrases in VT's lexical database ... for their vocal stamina, attention to the details of enunciation, and most of all, knowledge of IPA".[44]
Letters
The International Phonetic Association organizes the letters of the IPA into three categories: pulmonic consonants, non-pulmonic consonants, and vowels.[45][46]
Pulmonic consonant letters are arranged singly or in pairs of voiceless (tenuis) and voiced sounds, with these then grouped in columns from front (labial) sounds on the left to back (glottal) sounds on the right. In official publications by the IPA, two columns are omitted to save space, with the letters listed among 'other symbols' even though theoretically they belong in the main chart,[note 15] and with the remaining consonants arranged in rows from full closure (occlusives: stops and nasals), to brief closure (vibrants: trills and taps), to partial closure (fricatives) and minimal closure (approximants), again with a row left out to save space. In the table below, a slightly different arrangement is made: All pulmonic consonants are included in the pulmonic-consonant table, and the vibrants and laterals are separated out so that the rows reflect the common lenition pathway of stop → fricative → approximant, as well as the fact that several letters pull double duty as both fricative and approximant; affricates may be created by joining stops and fricatives from adjacent cells. Shaded cells represent articulations that are judged to be impossible.
Vowel letters are also grouped in pairs—of unrounded and rounded vowel sounds—with these pairs also arranged from front on the left to back on the right, and from maximal closure at top to minimal closure at bottom. No vowel letters are omitted from the chart, though in the past some of the mid central vowels were listed among the 'other symbols'.
Consonants
Pulmonic consonants
A pulmonic consonant is a consonant made by obstructing the glottis (the space between the vocal cords) or oral cavity (the mouth) and either simultaneously or subsequently letting out air from the lungs. Pulmonic consonants make up the majority of consonants in the IPA, as well as in human language. All consonants in English fall into this category.[47]
The pulmonic consonant table, which includes most consonants, is arranged in rows that designate manner of articulation, meaning how the consonant is produced, and columns that designate place of articulation, meaning where in the vocal tract the consonant is produced. The main chart includes only consonants with a single place of articulation.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Notes
- In rows where some letters appear in pairs (the obstruents), the letter to the right represents a voiced consonant (except breathy-voiced [ɦ]).[48] In the other rows (the sonorants), the single letter represents a voiced consonant.
- While IPA provides a single letter for the coronal places of articulation (for all consonants but fricatives), these do not always have to be used exactly. When dealing with a particular language, the letters may be treated as specifically dental, alveolar, or post-alveolar, as appropriate for that language, without diacritics.
- Shaded areas indicate articulations judged to be impossible.
- The letters [β, ð, ʁ, ʕ, ʢ] are canonically voiced fricatives but may be used for approximants.[49]
- In many languages, such as English, [h] and [ɦ] are not actually glottal, fricatives, or approximants. Rather, they are bare phonation.[50]
- It is primarily the shape of the tongue rather than its position that distinguishes the fricatives [ʃ ʒ], [ɕ ʑ], and [ʂ ʐ].
- [ʜ, ʢ] are defined as epiglottal fricatives under the "Other symbols" section in the official IPA chart, but they may be treated as trills at the same place of articulation as [ħ, ʕ] because trilling of the aryepiglottic folds typically co-occurs.[51]
- Some listed phones are not known to exist as phonemes in any language.
Non-pulmonic consonants
Non-pulmonic consonants are sounds whose airflow is not dependent on the lungs. These include clicks (found in the Khoisan languages and some neighboring Bantu languages of Africa), implosives (found in languages such as Sindhi, Hausa, Swahili and Vietnamese), and ejectives (found in many Amerindian and Caucasian languages).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Notes
- Clicks have traditionally been described as consisting of a forward place of articulation, commonly called the click 'type' or historically the 'influx', and a rear place of articulation, which when combined with the voicing, aspiration, nasalization, affrication, ejection, timing etc. of the click is commonly called the click 'accompaniment' or historically the 'efflux'. The IPA click letters indicate only the click type (forward articulation and release). Therefore, all clicks require two letters for proper notation: ⟨k͡ǂ, ɡ͡ǂ, ŋ͡ǂ, q͡ǂ, ɢ͡ǂ, ɴ͡ǂ⟩ etc., or with the order reversed if both the forward and rear releases are audible. The letter for the rear articulation is frequently omitted, in which case a ⟨k⟩ may usually be assumed. However, some researchers dispute the idea that clicks should be analyzed as doubly articulated, as the traditional transcription implies, and analyze the rear occlusion as solely a part of the airstream mechanism.[52] In transcriptions of such approaches, the click letter represents both places of articulation, with the different letters representing the different click types, and diacritics are used for the elements of the accompaniment: ⟨ǂ, ǂ̬, ǂ̃⟩ etc.
- Letters for the voiceless implosives ⟨ƥ, ƭ, ƈ, ƙ, ʠ⟩ are no longer supported by the IPA, though they remain in Unicode. Instead, the IPA typically uses the voiced equivalent with a voiceless diacritic: ⟨ɓ̥, ʛ̥⟩, etc..
- The letter for the retroflex implosive, ⟨ᶑ ⟩, is not "explicitly IPA approved" (Handbook, p. 166), but has the expected form if such a symbol were to be approved.
- The ejective diacritic is placed at the right-hand margin of the consonant, rather than immediately after the letter for the stop: ⟨t͜ʃʼ⟩, ⟨kʷʼ⟩. In imprecise transcription, it often stands in for a superscript glottal stop in glottalized but pulmonic sonorants, such as [mˀ], [lˀ], [wˀ], [aˀ] (also transcribable as creaky [m̰], [l̰], [w̰], [a̰]).
Affricates
Affricates and co-articulated stops are represented by two letters joined by a tie bar, either above or below the letters with no difference in meaning.[note 16] Affricates are optionally represented by ligatures (e.g. ⟨ʦ, ʣ, ʧ, ʤ, ʨ, ʥ, ꭧ, ꭦ ⟩), though this is no longer official IPA usage[1] because a great number of ligatures would be required to represent all affricates this way. Alternatively, a superscript notation for a consonant release is sometimes used to transcribe affricates, for example ⟨tˢ⟩ for [t͜s], paralleling [kˣ] ~ [k͜x]. The letters for the palatal plosives ⟨c⟩ and ⟨ɟ⟩ are often used as a convenience for [t͜ʃ] and [d͜ʒ] or similar affricates, even in official IPA publications, so they must be interpreted with care.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Co-articulated consonants
Co-articulated consonants are sounds that involve two simultaneous places of articulation (are pronounced using two parts of the vocal tract). In English, the [w] in "went" is a coarticulated consonant, being pronounced by rounding the lips and raising the back of the tongue. Similar sounds are [ʍ] and [ɥ]. In some languages, plosives can be double-articulated, for example in the name of Laurent Gbagbo.
|
Nasal
n͡m
Labial–alveolar
ŋ͡m
Labial–velar
Plosive
t͡p d͡b
Labial–alveolar
k͡p ɡ͡b
Labial–velar
q͡ʡ
Uvular–epiglottal
Fricative/approximant
ɥ̊ ɥ
Labial–palatal
ʍ w
Labial–velar
ɧ
Sj-sound (variable)
Lateral approximant
ɫ
Velarized alveolar
|
|
Notes
- [ɧ], the Swedish sj-sound, is described by the IPA as a "simultaneous [ʃ] and [x]", but it is unlikely such a simultaneous fricative actually exists in any language.[53]
- Multiple tie bars can be used: ⟨a͡b͡c⟩ or ⟨a͜b͜c⟩. For instance, if a prenasalized stop is transcribed ⟨m͡b⟩, and a doubly articulated stop ⟨ɡ͡b⟩, then a prenasalized doubly articulated stop would be ⟨ŋ͡m͡ɡ͡b⟩
- If a diacritic needs to be placed on or under a tie bar, the combining grapheme joiner (U+034F) needs to be used, as in [b͜͏̰də̀bdɷ̀] 'chewed' (Margi). Font support is spotty, however.
Vowels
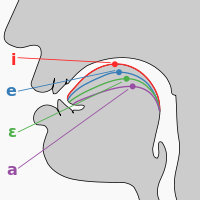
![X-ray photos show the sounds [i, u, a, ɑ].](http://upload.wikimedia.org/wikipedia/commons/1/15/Cardinal_vowels-Jones_x-ray.jpg)
The IPA defines a vowel as a sound which occurs at a syllable center.[54] Below is a chart depicting the vowels of the IPA. The IPA maps the vowels according to the position of the tongue.
| ||||||||||||||||||||||||||||||||
|
The vertical axis of the chart is mapped by vowel height. Vowels pronounced with the tongue lowered are at the bottom, and vowels pronounced with the tongue raised are at the top. For example, [ɑ] (the first vowel in father) is at the bottom because the tongue is lowered in this position. [i] (the vowel in "meet") is at the top because the sound is said with the tongue raised to the roof of the mouth.
In a similar fashion, the horizontal axis of the chart is determined by vowel backness. Vowels with the tongue moved towards the front of the mouth (such as [ɛ], the vowel in "met") are to the left in the chart, while those in which it is moved to the back (such as [ʌ], the vowel in "but") are placed to the right in the chart.
In places where vowels are paired, the right represents a rounded vowel (in which the lips are rounded) while the left is its unrounded counterpart.
Diphthongs
Diphthongs are typically specified with a non-syllabic diacritic, as in ⟨uɪ̯⟩ or ⟨u̯ɪ⟩, or with a superscript for the on- or off-glide, as in ⟨uᶦ⟩ or ⟨ᵘɪ⟩. Sometimes a tie bar is used: ⟨u͡ɪ⟩, especially if it is difficult to tell if the diphthong is characterized by an on-glide, an off-glide or is variable.
Notes
- ⟨a⟩ officially represents a front vowel, but there is little if any distinction between front and central open vowels (see Vowel § Acoustics), and ⟨a⟩ is frequently used for an open central vowel.[36] If disambiguation is required, the retraction diacritic or the centralized diacritic may be added to indicate an open central vowel, as in ⟨a̠⟩ or ⟨ä⟩.
Diacritics and prosodic notation
Diacritics are used for phonetic detail. They are added to IPA letters to indicate a modification or specification of that letter's normal pronunciation.[55]
By being made superscript, any IPA letter may function as a diacritic, conferring elements of its articulation to the base letter. Those superscript letters listed below are specifically provided for by the IPA Handbook; other uses can be illustrated with ⟨tˢ⟩ ([t] with fricative release), ⟨ᵗs⟩ ([s] with affricate onset), ⟨ⁿd⟩ (prenasalized [d]), ⟨bʱ⟩ ([b] with breathy voice), ⟨mˀ⟩ (glottalized [m]), ⟨sᶴ⟩ ([s] with a flavor of [ʃ]), ⟨oᶷ⟩ ([o] with diphthongization), ⟨ɯᵝ⟩ (compressed [ɯ]). Superscript diacritics placed after a letter are ambiguous between simultaneous modification of the sound and phonetic detail at the end of the sound. For example, labialized ⟨kʷ⟩ may mean either simultaneous [k] and [w] or else [k] with a labialized release. Superscript diacritics placed before a letter, on the other hand, normally indicate a modification of the onset of the sound (⟨mˀ⟩ glottalized [m], ⟨ˀm⟩ [m] with a glottal onset). (See § Superscript IPA.)
| Syllabicity diacritics | |||||
|---|---|---|---|---|---|
| ◌̩ | ɹ̩ n̩ | Syllabic | ◌̯ | ɪ̯ ʊ̯ | Non-syllabic |
| ◌̍ | ɻ̍ ŋ̍ | ◌̑ | y̑ | ||
| Consonant-release diacritics | |||||
| ◌ʰ | tʰ | Aspirated[a] | ◌̚ | p̚ | No audible release |
| ◌ⁿ | dⁿ | Nasal release | ◌ˡ | dˡ | Lateral release |
| ◌ᶿ | tᶿ | Voiceless dental fricative release | ◌ˣ | tˣ | Voiceless velar fricative release |
| ◌ᵊ | dᵊ | Mid central vowel release | |||
| Phonation diacritics | |||||
| ◌̥ | n̥ d̥ | Voiceless | ◌̬ | s̬ t̬ | Voiced |
| ◌̊ | ɻ̊ ŋ̊ | ||||
| ◌̤ | b̤ a̤ | Breathy voiced[a] | ◌̰ | b̰ a̰ | Creaky voiced |
| Articulation diacritics | |||||
| ◌̪ | t̪ d̪ | Dental | ◌̼ | t̼ d̼ | Linguolabial |
| ◌͆ | ɮ͆ | ||||
| ◌̺ | t̺ d̺ | Apical | ◌̻ | t̻ d̻ | Laminal |
| ◌̟ | u̟ t̟ | Advanced (fronted) | ◌̠ | i̠ t̠ | Retracted (backed) |
| ◌᫈ | ɡ᫈ | ◌̄ | q̄[b] | ||
| ◌̈ | ë ä | Centralized | ◌̽ | e̽ ɯ̽ | Mid-centralized |
| ◌̝ | e̝ r̝ | Raised ([r̝], [ɭ˔] are fricatives) |
◌̞ | e̞ β̞ | Lowered ([β̞], [ɣ˕] are approximants) |
| ◌˔ | ɭ˔ | ◌˕ | y˕ ɣ˕ | ||
| Co-articulation diacritics | |||||
| ◌̹ | ɔ̹ x̹ | More rounded (over-rounding) |
◌̜ | ɔ̜ xʷ̜ | Less rounded (under-rounding)[c] |
| ◌͗ | y͗ χ͗ | ◌͑ | y͑ χ͑ʷ | ||
| ◌ʷ | tʷ dʷ | Labialized | ◌ʲ | tʲ dʲ | Palatalized |
| ◌ˠ | tˠ dˠ | Velarized | ◌̴ | ɫ ᵶ | Velarized or pharyngealized |
| ◌ˤ | tˤ aˤ | Pharyngealized | |||
| ◌̘ | e̘ o̘ | Advanced tongue root | ◌̙ | e̙ o̙ | Retracted tongue root |
| ◌꭪ | y꭪ | ◌꭫ | y꭫ | ||
| ◌̃ | ẽ z̃ | Nasalized | ◌˞ | ɚ ɝ | Rhoticity |
Notes
- ^a With aspirated voiced consonants, the aspiration is usually also voiced (voiced aspirated – but see voiced consonants with voiceless aspiration). Many linguists prefer one of the diacritics dedicated to breathy voice over simple aspiration, such as ⟨b̤⟩. Some linguists restrict that diacritic to sonorants, such as breathy-voice ⟨m̤⟩, and transcribe voiced-aspirated obstruents as e.g. ⟨bʱ⟩.
- ^b Care must be taken that a superscript retraction sign is not mistaken for mid tone.
- ^c These are relative to the cardinal value of the letter. They can also apply to unrounded vowels: [ɛ̜] is more spread (less rounded) than cardinal [ɛ], and [ɯ̹] is less spread than cardinal [ɯ].[56]
Since ⟨xʷ⟩ can mean that the [x] is labialized (rounded) throughout its articulation, and ⟨x̜⟩ makes no sense ([x] is already completely unrounded), ⟨x̜ʷ⟩ can only mean a less-labialized/rounded [xʷ]. However, readers might mistake ⟨x̜ʷ⟩ for "[x̜]" with a labialized off-glide, or might wonder if the two diacritics cancel each other out. Placing the 'less rounded' diacritic under the labialization diacritic, ⟨xʷ̜⟩, makes it clear that it is the labialization that is 'less rounded' than its cardinal IPA value.
Subdiacritics (diacritics normally placed below a letter) may be moved above a letter to avoid conflict with a descender, as in voiceless ⟨ŋ̊⟩.[55] The raising and lowering diacritics have optional spacing forms ⟨˔⟩, ⟨˕⟩ that avoid descenders.
The state of the glottis can be finely transcribed with diacritics. A series of alveolar plosives ranging from open-glottis to closed-glottis phonation is:
| Open glottis | [t] | voiceless |
|---|---|---|
| [d̤] | breathy voice, also called murmured | |
| [d̥] | slack voice | |
| Sweet spot | [d] | modal voice |
| [d̬] | stiff voice | |
| [d̰] | creaky voice | |
| Closed glottis | [ʔ͡t] | glottal closure |
Additional diacritics are provided by the Extensions to the IPA for speech pathology.
Suprasegmentals
These symbols describe the features of a language above the level of individual consonants and vowels, that is, at the level of syllable, word or phrase. These include prosody, pitch, length, stress, intensity, tone and gemination of the sounds of a language, as well as the rhythm and intonation of speech.[57] Various ligatures of pitch/tone letters and diacritics are provided for by the Kiel convention and used in the IPA Handbook despite not being found in the summary of the IPA alphabet found on the one-page chart.
Under capital letters below we will see how a carrier letter may be used to indicate suprasegmental features such as labialization or nasalization. Some authors omit the carrier letter, for e.g. suffixed [kʰuˣt̪s̟]ʷ or prefixed [ʷkʰuˣt̪s̟],[58] or place a spacing variant of a diacritic such as ⟨˔⟩ or ⟨˜⟩ at the beginning or end of a word to indicate that it applies to the entire word.[59]
| Length, stress, and rhythm | |||
|---|---|---|---|
| ˈke | Primary stress (appears before stressed syllable) |
ˌke | Secondary stress (appears before stressed syllable) |
| eː kː | Long (long vowel or geminate consonant) |
eˑ | Half-long |
| ə̆ ɢ̆ | Extra-short | ||
| ek.ste eks.te |
Syllable break (internal boundary) |
es‿e | Linking (lack of a boundary; a phonological word)[note 17] |
| Intonation | |||
| | | Minor or foot break | ‖ | Major or intonation break |
| ↗︎ | Global rise[note 18] | ↘︎ | Global fall[note 18] |
| Up- and down-step | |||
| ꜛke | Upstep | ꜜke | Downstep |
| Pitch diacritics[note 19] | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ŋ̋ e̋ | Extra high | ŋ̌ ě | Rising | ŋ᷄ e᷄ | Mid-rising | |||||||
| ŋ́ é | High | ŋ̂ ê | Falling | ŋ᷅ e᷅ | Low-rising | |||||||
| ŋ̄ ē | Mid | ŋ᷈ e᷈ | Peaking (rising–falling) | ŋ᷇ e᷇ | High-falling | |||||||
| ŋ̀ è | Low | ŋ᷉ e᷉ | Dipping (falling–rising) | ŋ᷆ e᷆ | Mid-falling | |||||||
| ŋ̏ ȅ | Extra low | (etc.)[note 20] | ||||||||||
| Chao tone letters[note 19] | ||||
|---|---|---|---|---|
| ˥e | ꜒e | e˥ | e꜒ | High |
| ˦e | ꜓e | e˦ | e꜓ | Half-high |
| ˧e | ꜔e | e˧ | e꜔ | Mid |
| ˨e | ꜕e | e˨ | e꜕ | Half-low |
| ˩e | ꜖e | e˩ | e꜖ | Low |
| ˩˥e | ꜖꜒e | e˩˥ | e꜖꜒ | Rising (low to high or generic) |
| ˥˩e | ꜒꜖e | e˥˩ | e꜒꜖ | Falling (high to low or generic) |
| (etc.) | ||||
The old staveless tone letters, which are effectively obsolete, include high ⟨ˉe⟩, mid ⟨˗e⟩, low ⟨ˍe⟩, rising ⟨ˊe⟩ and falling ⟨ˋe⟩.
Stress
Officially, the stress marks ⟨ˈ ˌ⟩ appear before the stressed syllable, and thus mark the syllable boundary as well as stress (though the syllable boundary may still be explicitly marked with a period).[60] Occasionally the stress mark is placed immediately before the nucleus of the syllable, after any consonantal onset.[61] In such transcriptions, the stress mark does not mark a syllable boundary. The primary stress mark may be doubled ⟨ˈˈ⟩ for extra stress (such as prosodic stress). The secondary stress mark is sometimes seen doubled ⟨ˌˌ⟩ for extra-weak stress, but this convention has not been adopted by the IPA.[60] Some dictionaries place both stress marks before a syllable, ⟨¦⟩, to indicate that pronunciations with either primary or secondary stress are heard, though this is not IPA usage.[62]
Boundary markers
There are three boundary markers: ⟨.⟩ for a syllable break, ⟨|⟩ for a minor prosodic break and ⟨‖⟩ for a major prosodic break. The tags 'minor' and 'major' are intentionally ambiguous. Depending on need, 'minor' may vary from a foot break to a break in list-intonation to a continuing–prosodic unit boundary (equivalent to a comma), and while 'major' is often any intonation break, it may be restricted to a final–prosodic unit boundary (equivalent to a period). The 'major' symbol may also be doubled, ⟨‖‖⟩, for a stronger break.[note 21]
Although not part of the IPA, the following additional boundary markers are often used in conjunction with the IPA: ⟨μ⟩ for a mora or mora boundary, ⟨σ⟩ for a syllable or syllable boundary, ⟨+⟩ for a morpheme boundary, ⟨#⟩ for a word boundary (may be doubled, ⟨##⟩, for e.g. a breath-group boundary),[64] ⟨$⟩ for a phrase or intermediate boundary and ⟨%⟩ for a prosodic boundary. For example, C# is a word-final consonant, %V a post-pausa vowel, and T% an IU-final tone (edge tone).
Pitch and tone
⟨ꜛ ꜜ⟩ are defined in the Handbook as "upstep" and "downstep", concepts from tonal languages. However, the upstep symbol can also be used for pitch reset, and the IPA Handbook uses it for prosody in the illustration for Portuguese, a non-tonal language.
Phonetic pitch and phonemic tone may be indicated by either diacritics placed over the nucleus of the syllable (e.g., high-pitch ⟨é⟩) or by Chao tone letters placed either before or after the word or syllable. There are three graphic variants of the tone letters: with or without a stave, and facing left or facing right from the stave. The stave was introduced with the 1989 Kiel Convention, as was the option of placing a staved letter after the word or syllable, while retaining the older conventions. There are therefore six ways to transcribe pitch/tone in the IPA: i.e., ⟨é⟩, ⟨˦e⟩, ⟨e˦⟩, ⟨꜓e⟩, ⟨e꜓⟩ and ⟨ˉe⟩ for a high pitch/tone.[60][65][66] Of the tone letters, only left-facing staved letters and a few representative combinations are shown in the summary on the Chart, and in practice it is currently more common for tone letters to occur after the syllable/word than before, as in the Chao tradition. Placement before the word is a carry-over from the pre-Kiel IPA convention, as is still the case for the stress and upstep/downstep marks. The IPA endorses the Chao tradition of using the left-facing tone letters, ⟨˥ ˦ ˧ ˨ ˩⟩, for underlying tone, and the right-facing letters, ⟨꜒ ꜓ ꜔ ꜕ ꜖⟩, for surface tone, as occurs in tone sandhi, and for the intonation of non-tonal languages.[note 22] In the Portuguese illustration in the 1999 Handbook, tone letters are placed before a word or syllable to indicate prosodic pitch (equivalent to [↗︎] global rise and [↘︎] global fall, but allowing more precision), and in the Cantonese illustration they are placed after a word/syllable to indicate lexical tone. Theoretically therefore prosodic pitch and lexical tone could be simultaneously transcribed in a single text, though this is not a formalized distinction.
Rising and falling pitch, as in contour tones, are indicated by combining the pitch diacritics and letters in the table, such as grave plus acute for rising [ě] and acute plus grave for falling [ê]. Only six combinations of two diacritics are supported, and only across three levels (high, mid, low), despite the diacritics supporting five levels of pitch in isolation. The four other explicitly approved rising and falling diacritic combinations are high/mid rising [e᷄], low rising [e᷅], high falling [e᷇], and low/mid falling [e᷆].[note 23]
The Chao tone letters, on the other hand, may be combined in any pattern, and are therefore used for more complex contours and finer distinctions than the diacritics allow, such as mid-rising [e˨˦], extra-high falling [e˥˦], etc. There are 20 such possibilities. However, in Chao's original proposal, which was adopted by the IPA in 1989, he stipulated that the half-high and half-low letters ⟨˦ ˨⟩ may be combined with each other, but not with the other three tone letters, so as not to create spuriously precise distinctions. With this restriction, there are 8 possibilities.[67]
The old staveless tone letters tend to be more restricted than the staved letters, though not as restricted as the diacritics. Officially, they support as many distinctions as the staved letters,[68] but typically only three pitch levels are distinguished. Unicode supports default or high-pitch ⟨ˉ ˊ ˋ ˆ ˇ ˜ ˙⟩ and low-pitch ⟨ˍ ˏ ˎ ꞈ ˬ ˷⟩. Only a few mid-pitch tones are supported (such as ⟨˗ ˴⟩), and then only accidentally.
Although tone diacritics and tone letters are presented as equivalent on the chart, "this was done only to simplify the layout of the chart. The two sets of symbols are not comparable in this way."[69] Using diacritics, a high tone is ⟨é⟩ and a low tone is ⟨è⟩; in tone letters, these are ⟨e˥⟩ and ⟨e˩⟩. One can double the diacritics for extra-high ⟨e̋⟩ and extra-low ⟨ȅ⟩; there is no parallel to this using tone letters. Instead, tone letters have mid-high ⟨e˦⟩ and mid-low ⟨e˨⟩; again, there is no equivalent among the diacritics.
The correspondence breaks down even further once they start combining. For more complex tones, one may combine three or four tone diacritics in any permutation,[60] though in practice only generic peaking (rising-falling) e᷈ and dipping (falling-rising) e᷉ combinations are used. Chao tone letters are required for finer detail (e˧˥˧, e˩˨˩, e˦˩˧, e˨˩˦, etc.). Although only 10 peaking and dipping tones were proposed in Chao's original, limited set of tone letters, phoneticians often make finer distinctions, and indeed an example is found on the IPA Chart.[note 24] The system allows the transcription of 112 peaking and dipping pitch contours, including tones that are level for part of their length.
| Register | Level [note 26] |
Rising | Falling | Peaking | Dipping |
|---|---|---|---|---|---|
| e˩ | e˩˩ | e˩˧ | e˧˩ | e˩˧˩ | e˧˩˧ |
| e˨ | e˨˨ | e˨˦ | e˦˨ | e˨˦˨ | e˦˨˦ |
| e˧ | e˧˧ | e˧˥ | e˥˧ | e˧˥˧ | e˥˧˥ |
| e˦ | e˦˦ | e˧˥˩ | e˧˩˥ | ||
| e˥ | e˥˥ | e˩˥ | e˥˩ | e˩˥˧ | e˥˩˧ |
More complex contours are possible. Chao gave an example of [꜔꜒꜖꜔] (mid-high-low-mid) from English prosody.[67]
Chao tone letters generally appear after each syllable, for a language with syllable tone (⟨a˧vɔ˥˩⟩), or after the phonological word, for a language with word tone (⟨avɔ˧˥˩⟩). The IPA gives the option of placing the tone letters before the word or syllable (⟨˧a˥˩vɔ⟩, ⟨˧˥˩avɔ⟩), but this is rare for lexical tone. (And indeed reversed tone letters may be used to clarify that they apply to the following rather than to the preceding syllable: ⟨꜔a꜒꜖vɔ⟩, ⟨꜔꜒꜖avɔ⟩.) The staveless letters are not directly supported by Unicode, but some fonts allow the stave in Chao tone letters to be suppressed.
Comparative degree
IPA diacritics may be doubled to indicate an extra degree of the feature indicated.[70] This is a productive process, but apart from extra-high and extra-low tones ⟨ə̋, ə̏⟩ being marked by doubled high- and low-tone diacritics, and the major prosodic break ⟨‖⟩ being marked as a double minor break ⟨|⟩, it is not specifically regulated by the IPA. (Note that transcription marks are similar: double slashes indicate extra (morpho)-phonemic, double square brackets especially precise, and double parentheses especially unintelligible.)
For example, the stress mark may be doubled to indicate an extra degree of stress, such as prosodic stress in English.[71] An example in French, with a single stress mark for normal prosodic stress at the end of each prosodic unit (marked as a minor prosodic break), and a double stress mark for contrastive/emphatic stress: [ˈˈɑ̃ːˈtre | məˈsjø ‖ ˈˈvwala maˈdam ‖] Entrez monsieur, voilà madame.[72] Similarly, a doubled secondary stress mark ⟨ˌˌ⟩ is commonly used for tertiary (extra-light) stress.[73] In a similar vein, the effectively obsolete (though never retired) staveless tone letters were once doubled for an emphatic rising intonation ⟨˶⟩ and an emphatic falling intonation ⟨˵⟩.[74]
Length is commonly extended by repeating the length mark, as in English shhh! [ʃːːː], or for "overlong" segments in Estonian:
- vere /vere/ 'blood [gen.sg.]', veere /veːre/ 'edge [gen.sg.]', veere /veːːre/ 'roll [imp. 2nd sg.]'
- lina /linɑ/ 'sheet', linna /linːɑ/ 'town [gen. sg.]', linna /linːːɑ/ 'town [ine. sg.]'
(Normally additional degrees of length are handled by the extra-short or half-long diacritic, but the first two words in each of the Estonian examples are analyzed as simply short and long, requiring a different remedy for the final words.)
Occasionally other diacritics are doubled:
- Rhoticity in Badaga /be/ "mouth", /be˞/ "bangle", and /be˞˞/ "crop".[75]
- Mild and strong aspirations, [kʰ], [kʰʰ].[note 27]
- Nasalization, as in Palantla Chinantec lightly nasalized /ẽ/ vs heavily nasalized /e͌/,[76] though in extIPA the latter indicates velopharyngeal frication.
- Weak vs strong ejectives, [kʼ], [kˮ].[77]
- Especially lowered, e.g. [t̞̞] (or [t̞˕], if the former symbol does not display properly) for /t/ as a weak fricative in some pronunciations of register.[78]
- Especially retracted, e.g. [ø̠̠] or [s̠̠],[79][70][80] though some care might be needed to distinguish this from indications of alveolar or alveolarized articulation in extIPA, e.g. [s͇].
- The transcription of strident and harsh voice as extra-creaky /a᷽/ may be motivated by the similarities of these phonations.
Ambiguous characters
A number of IPA characters are not consistently used for their official values. A distinction between voiced fricatives and approximants is only partially implemented, for example. Even with the relatively recent addition of the palatal fricative ⟨ʝ⟩ and the velar approximant ⟨ɰ⟩ to the alphabet, other letters, though defined as fricatives, are often ambiguous between fricative and approximant. For forward places, ⟨β⟩ and ⟨ð⟩ can generally be assumed to be fricatives unless they carry a lowering diacritic. Rearward, however, ⟨ʁ⟩ and ⟨ʕ⟩ are perhaps more commonly intended to be approximants even without a lowering diacritic. ⟨h⟩ and ⟨ɦ⟩ are similarly either fricatives or approximants, depending on the language, or even glottal "transitions", without that often being specified in the transcription.
Another common ambiguity is among the palatal consonants. ⟨c⟩ and ⟨ɟ⟩ are not uncommonly used as a typographic convenience for affricates, typically [t͜ʃ] and [d͜ʒ], while ⟨ɲ⟩ and ⟨ʎ⟩ are commonly used for palatalized alveolar [n̠ʲ] and [l̠ʲ]. To some extent this may be an effect of analysis, but it is often common for people to match up available letters to the sounds of a language, without overly worrying whether they are phonetically accurate.
It has been argued that the lower-pharyngeal (epiglottal) fricatives ⟨ʜ⟩ and ⟨ʢ⟩ are better characterized as trills, rather than as fricatives that have incidental trilling.[81] This has the advantage of merging the upper-pharyngeal fricatives [ħ, ʕ] together with the epiglottal plosive [ʡ] and trills [ʜ ʢ] into a single pharyngeal column in the consonant chart. However, in Shilha Berber the epiglottal fricatives are not trilled.[82][83] Although they might be transcribed ⟨ħ̠ ʢ̠⟩ to indicate this, the far more common transcription is ⟨ʜ ʢ⟩, which is therefore ambiguous between languages.
Among vowels, ⟨a⟩ is officially a front vowel, but is more commonly treated as a central vowel. The difference, to the extent it is even possible, is not phonemic in any language.
Three letters are not needed, but are retained due to inertia and would be hard to justify today by the standards of the modern IPA. ⟨ʍ⟩ appears because it is found in English; officially it is a fricative, with terminology dating to the days before 'fricative' and 'approximant' were distinguished. Based on how all other fricatives and approximants are transcribed, one would expect either ⟨xʷ⟩ for a fricative (not how it is actually used) or ⟨w̥⟩ for an approximant. Indeed, outside of English transcription, that is what is more commonly found in the literature. ⟨ɱ⟩ is another historic remnant. Although a common allophone of [m] in particular It is only phonemically distinct in a single language (Kukuya), a fact that was discovered after it was standardized in the IPA. A number of consonants without dedicated IPA letters are found in many more languages than that; ⟨ɱ⟩ is retained because of its historical use for European languages, where it could easily be normalized to ⟨m̪⟩. There have been several votes to retire ⟨ɱ⟩ from the IPA, but so far they have failed. Finally, ⟨ɧ⟩ is officially a simultaneous postalveolar and velar fricative, a realization that does not appear to exist in any language. It is retained because it is convenient for the transcription of Swedish, where it is used for a consonant that has various realizations in different dialects. That is, it is not actually a phonetic character at all, but a phonemic one, which is officially beyond the purview of the IPA alphabet.
For all phonetic notation, it is good practice for an author to specify exactly what they mean by the symbols that they use.
Superscript IPA
Superscript IPA letters may be used to indicate secondary articulation, releases and other transitions, shades of sound, epenthetic and incompletely articulated sounds. In 2020, the International Phonetic Association endorsed the encoding of superscript IPA letters in a proposal to the Unicode Commission for broader coverage of the IPA alphabet. The proposal covered all IPA letters that were not yet supported (apart from the tone letters), including the implicit retroflex letters ⟨ꞎ 𝼅 𝼈 ᶑ 𝼊 ⟩, as well as the two length marks ⟨ː ˑ⟩ and old-style affricate ligatures.[35][84] A separate request by the International Clinical Phonetics and Linguistics Association for an expansion of extIPA coverage endorsed superscript variants of all extIPA fricative letters, specifically for the fricative release of consonants.[85] Unicode placed the new superscript ("modifier") letters in a new Latin Extended-F block.
The Unicode characters for superscript (modifier) IPA and extIPA letters are as follows. Characters for sounds with secondary articulation are set off in parentheses and placed below the base letters:
| Bilabial | Labiodental | Dental | Alveolar | Postalveolar | Retroflex | Palatal | Velar | Uvular | Pharyngeal | Glottal | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nasal | m ᵐ 1D50 |
ɱ ᶬ 1DAC |
n ⁿ 207F |
ɳ ᶯ 1DAF |
ɲ ᶮ 1DAE |
ŋ ᵑ 1D51 |
ɴ ᶰ 1DB0 |
|||||||||||||||
| Plosive | p ᵖ 1D56 |
b ᵇ 1D47 |
t ᵗ 1D57 |
d ᵈ 1D48 |
ʈ 𐞯 107AF |
ɖ 𐞋 1078B |
c ᶜ 1D9C |
ɟ ᶡ 1DA1 |
k ᵏ 1D4F |
ɡ ᶢ/g ᵍ 1DA2/1D4D |
q 𐞥 107A5 |
ɢ 𐞒 10792 |
ʡ 𐞳 107B3 |
ʔ ˀ 2C0 | ||||||||
| Affricate | ʦ 𐞬 107AC |
ʣ 𐞇 10787 |
ʧ 𐞮 107AE (ʨ 𐞫) 107AB |
ʤ 𐞊 1078A (ʥ 𐞉) 10789 |
ꭧ 𐞭 107AD |
ꭦ 𐞈 10788 |
||||||||||||||||
| Fricative | ɸ ᶲ 1DB2 |
β ᵝ 1D5D |
f ᶠ 1DA0 |
v ᵛ 1D5B |
θ ᶿ 1DBF |
ð ᶞ 1D9E |
s ˢ 2E2 |
z ᶻ 1DBB |
ʃ ᶴ 1DB4 (ɕ ᶝ) 1D9D |
ʒ ᶾ 1DBE (ʑ ᶽ) 1DBD |
ʂ ᶳ 1DB3 |
ʐ ᶼ 1DBC |
ç ᶜ̧ [note 28] |
ʝ ᶨ 1DA8 |
x ˣ 2E3 (ɧ 𐞗) 10797 |
ɣ ˠ 2E0 |
χ ᵡ 1D61 |
ʁ ʶ 2B6 |
ħ 𐞕 10795 (ʩ 𐞐) 10790 |
ʕ ˤ, ˁ 2E4, 2C1 [note 29] |
h ʰ 2B0 |
ɦ ʱ 2B1 |
| Approximant | ʋ ᶹ 1DB9 |
ɹ ʴ 2B4 |
ɻ ʵ 2B5 |
j ʲ 2B2 (ɥ ᶣ) 1DA3 |
(ʍ ꭩ) AB69 | ɰ ᶭ 1DAD (w ʷ) 2B7 |
||||||||||||||||
| Tap/flap | ⱱ 𐞰 107B0 |
ɾ 𐞩 107A9 |
ɽ 𐞨 107A8 |
|||||||||||||||||||
| Trill | ʙ 𐞄 10784 |
r ʳ 2B3 |
ʀ 𐞪 107AA |
ʜ 𐞖 10796 |
ʢ 𐞴 107B4 |
|||||||||||||||||
| Lateral fricative | ɬ 𐞛 1079B (ʪ 𐞙) 10799 |
ɮ 𐞞 1079E (ʫ 𐞚) 1079A |
ꞎ 𐞝 1079D |
𝼅 𐞟 1079F |
𝼆 𐞡 107A1 |
𝼄 𐞜 1079C |
||||||||||||||||
| Lateral approximant | l ˡ 2E1 (ɫ ꭞ) AB5E [note 30] |
ɭ ᶩ 1DA9 |
ʎ 𐞠 107A0 |
ʟ ᶫ 1DAB |
||||||||||||||||||
| Lateral tap/flap | ɺ 𐞦 107A6 |
𝼈 𐞧 107A7 |
||||||||||||||||||||
| Implosive | ɓ 𐞅 10785 |
ɗ 𐞌 1078C |
ᶑ 𐞍 1078D |
ʄ 𐞘 10798 |
ɠ 𐞓 10793 |
ʛ 𐞔 10794 |
||||||||||||||||
| Click release | ʘ 𐞵 107B5 |
ǀ 𐞶 107B6 |
ǃ ꜝ A71D (¡ ꜞ) A71E [note 31] |
𝼊 𐞹 107B9 |
ǂ 𐞸 107B8 |
|||||||||||||||||
| Lateral click release |
ǁ 𐞷 107B7 |
|||||||||||||||||||||
The spacing diacritic for ejective consonants, U+2BC, works with superscript letters despite not being superscript itself: ⟨ᵖʼ ᵗʼ ᶜʼ ᵏˣʼ⟩. If a distinction needs to be made, the combining apostrophe U+315 may be used: ⟨ᵖ̕ ᵗ̕ ᶜ̕ ᵏˣ̕⟩. The spacing diacritic should be used for a baseline letter with a superscript release, such as [tˢʼ] or [kˣʼ], where the scope of the apostrophe includes the non-superscript letter, but the combining apostrophe U+315 might be used to indicate a weakly articulated ejective consonant, where the whole consonant is written as a superscript, or together with U+2BC when separate apostrophes have scope over the base and modifier letters, as in ⟨pʼᵏˣ̕⟩.[84]
| Front | Central | Back | ||||
|---|---|---|---|---|---|---|
| Close | i ⁱ 2071 |
y ʸ 2B8 |
ɨ ᶤ 1DA4 |
ʉ ᶶ 1DB6 |
ɯ ᵚ 1D5A |
u ᵘ 1D58 |
| Near-close | ɪ ᶦ 1DA6 (ɩ ᶥ) 1DA5 |
ʏ 𐞲 107B2 |
ᵻ ᶧ 1DA7 |
ʊ ᶷ 1DB7 (ɷ 𐞤) 107A4 | ||
| Close-mid | e ᵉ 1D49 |
ø 𐞢 107A2 |
ɘ 𐞎 1078E |
ɵ ᶱ 1DB1 |
ɤ 𐞑 10791 |
o ᵒ 1D52 |
| Mid | ə ᵊ 1D4A |
|||||
| Open-mid | ɛ ᵋ 1D4B |
œ ꟹ A7F9 |
ɜ ᶟ 1D9F [note 32] |
ɞ 𐞏 1078F |
ʌ ᶺ 1DBA |
ɔ ᵓ 1D53 |
| Near-open | æ 𐞃 10783 [note 33] |
ɶ 𐞣 107A3 |
ɐ ᵄ 1D44 |
ɑ ᵅ 1D45 |
ɒ ᶛ 1D9B | |
| Open | a ᵃ 1D43 |
|||||
Note that the para-IPA letter for a central reduced vowel, ⟨ᵻ⟩, is supported, but its rounded equivalent, ⟨ᵿ⟩, is not.
The precomposed Unicode rhotic vowel letters ⟨ɚ ɝ⟩ are not supported. The rhotic diacritic should be used instead: ⟨ᵊ˞ ᶟ˞⟩.[35]
| Long | Half-long |
|---|---|
| ː 𐞁 10781 |
ˑ 𐞂 10782 |
Superscript length marks can be used for indicating the length of aspiration of a consonant, e.g. [pʰ tʰ𐞂 kʰ𐞁]. Another option is to double the diacritic: ⟨kʰʰ⟩.[35]
Superscript letters can be meaningfully modified by combining diacritics, just as baseline letters are. For example, a superscript dental nasal is ⟨ⁿ̪d̪⟩, a superscript voiceless velar nasal is ⟨ᵑ̊ǂ⟩, and labial-velar prenasalization is ⟨ᵑ͡ᵐɡ͡b⟩. Although the diacritic may seem a bit oversized compared to the superscript letter it modifies, this can be an aid to legibility, just as it is with the composite superscript c-cedilla and rhotic vowels: ⟨ᵓ̃⟩.
Spacing diacritics, however, as in ⟨tʲ⟩, cannot be secondarily superscripted in plain text: ⟨ᵗʲ⟩.[note 34]
Superscript wildcards are partially supported: e.g. ᴺC (prenasalized consonant), ꟲN (prestopped nasal), Pꟳ (fricative release), NᴾF (epenthetic plosive), CVNᵀ (tone-bearing syllable), Cᴸ (liquid or lateral release), Cᴿ (rhotic or resonant release), Vᴳ (off-glide/diphthong), Cⱽ (fleeting vowel). However, superscript S for sibilant release and superscript Ʞ for fleeting/epenthetic click are not supported as of Unicode 16. Other basic Latin superscript wildcards for tone and weak indeterminate sounds, as described below, are mostly supported:
- ᴬ ᴮ ꟲ ᴰ ᴱ ꟳ ᴳ ᴴ ᴵ ᴶ ᴷ ᴸ ᴹ ᴺ ᴼ ᴾ ꟴ ᴿ – ᵀ ᵁ ⱽ ᵂ – – –.
Obsolete and nonstandard symbols
A number of IPA letters and diacritics have been retired or replaced over the years. This number includes duplicate symbols, symbols that were replaced due to user preference, and unitary symbols that were rendered with diacritics or digraphs to reduce the inventory of the IPA. The rejected symbols are now considered obsolete, though some are still seen in the literature.
The IPA once had several pairs of duplicate symbols from alternative proposals, but eventually settled on one or the other. An example is the vowel letter ⟨ɷ⟩, rejected in favor of ⟨ʊ⟩. Affricates were once transcribed with ligatures, such as ⟨ʦ ʣ, ʧ ʤ, ʨ ʥ, ꭧ ꭦ ⟩ (and others not found in Unicode). These have been officially retired but are still used. Letters for specific combinations of primary and secondary articulation have also been mostly retired, with the idea that such features should be indicated with tie bars or diacritics: ⟨ƍ⟩ for [zʷ] is one. In addition, the rare voiceless implosives, ⟨ƥ ƭ ƈ ƙ ʠ ⟩, were dropped soon after their introduction and are now usually written ⟨ɓ̥ ɗ̥ ʄ̊ ɠ̊ ʛ̥ ⟩. The original set of click letters, ⟨ʇ, ʗ, ʖ, ʞ⟩, was retired but is still sometimes seen, as the current pipe letters ⟨ǀ, ǃ, ǁ, ǂ⟩ can cause problems with legibility, especially when used with brackets ([ ] or / /), the letter ⟨l⟩, or the prosodic marks ⟨|, ‖⟩. (For this reason, some publications which use the current IPA pipe letters disallow IPA brackets.)[86]
Individual non-IPA letters may find their way into publications that otherwise use the standard IPA. This is especially common with:
- Affricates, such as the Americanist barred lambda ⟨ƛ⟩ for [t͜ɬ] or ⟨č⟩ for [t͜ʃ ].[note 35]
- The Karlgren letters for Chinese vowels, ⟨ɿ, ʅ , ʮ, ʯ ⟩
- Digits for tonal phonemes that have conventional numbers in a local tradition, such as the four tones of Standard Chinese. This may be more convenient for comparison between related languages and dialects than a phonetic transcription would be, because tones vary more unpredictably than segmental phonemes do.
- Digits for tone levels, which are simpler to typeset, though the lack of standardization can cause confusion (e.g. ⟨1⟩ is high tone in some languages but low tone in others; ⟨3⟩ may be high, medium or low tone, depending on the local convention).
- Iconic extensions of standard IPA letters that can be readily understood, such as retroflex ⟨ᶑ ⟩ and ⟨ꞎ⟩. These are referred to in the Handbook and have been included in IPA requests for Unicode support.
In addition, it is common to see ad hoc typewriter substitutions, generally capital letters, for when IPA support is not available, e.g. A for ⟨ɑ⟩, B for ⟨β⟩ or ⟨ɓ⟩, D for ⟨ð⟩, ⟨ɗ ⟩ or ⟨ɖ ⟩, E for ⟨ɛ⟩, F or P for ⟨ɸ⟩, G ⟨ɣ⟩, I ⟨ɪ⟩, L ⟨ɬ⟩, N ⟨ŋ⟩, O ⟨ɔ⟩, S ⟨ ʃ ⟩, T ⟨θ⟩ or ⟨ʈ ⟩, U ⟨ʊ⟩, V ⟨ʋ⟩, X ⟨χ⟩, Z ⟨ʒ⟩, as well as @ for ⟨ə⟩ and 7 or ? for ⟨ʔ⟩. (See also SAMPA and X-SAMPA substitute notation.)
Extensions

The Extensions to the International Phonetic Alphabet for Disordered Speech, commonly abbreviated "extIPA" and sometimes called "Extended IPA", are symbols whose original purpose was to accurately transcribe disordered speech. At the Kiel Convention in 1989, a group of linguists drew up the initial extensions,[87] which were based on the previous work of the PRDS (Phonetic Representation of Disordered Speech) Group in the early 1980s.[88] The extensions were first published in 1990, then modified, and published again in 1994 in the Journal of the International Phonetic Association, when they were officially adopted by the ICPLA.[89] While the original purpose was to transcribe disordered speech, linguists have used the extensions to designate a number of sounds within standard communication, such as hushing, gnashing teeth, and smacking lips,[2] as well as regular lexical sounds such as lateral fricatives that do not have standard IPA symbols.
In addition to the Extensions to the IPA for disordered speech, there are the conventions of the Voice Quality Symbols, which include a number of symbols for additional airstream mechanisms and secondary articulations in what they call "voice quality".
Associated notation
Capital letters and various characters on the number row of the keyboard are commonly used to extend the alphabet in various ways.
Associated symbols
There are various punctuation-like conventions for linguistic transcription that are commonly used together with IPA. Some of the more common are:
- ⟨*⟩
- (a) A reconstructed form.
- (b) An ungrammatical form (including an unphonemic form).
- ⟨**⟩
- (a) A reconstructed form, deeper (more ancient) than a single ⟨*⟩, used when reconstructing even further back from already-starred forms.
- (b) An ungrammatical form. A less common convention than ⟨*⟩ (b), this is sometimes used when reconstructed and ungrammatical forms occur in the same text.[90]
- ⟨×⟩
- An ungrammatical form. A less common convention than ⟨*⟩ (b), this is sometimes used when reconstructed and ungrammatical forms occur in the same text.[91]
- ⟨?⟩
- A doubtfully grammatical form.
- ⟨%⟩
- A generalized form, such as a typical shape of a wanderwort that has not actually been reconstructed.[92]
- ⟨#⟩
- A word boundary – e.g. ⟨#V⟩ for a word-initial vowel.
- ⟨$⟩
- A phonological word boundary; e.g. ⟨H$⟩ for a high tone that occurs in such a position.
Capital letters
Full capital letters are not used as IPA symbols, except as typewriter substitutes (e.g. N for ⟨ŋ⟩, S for ⟨ʃ⟩, O for ⟨ɔ⟩ – see SAMPA). They are, however, often used in conjunction with the IPA in two cases:
- for (archi)phonemes and for natural classes of sounds (that is, as wildcards). The extIPA chart, for example, uses capital letters as wildcards in its illustrations.
- as carrying letters for the Voice Quality Symbols.
Wildcards are commonly used in phonology to summarize syllable or word shapes, or to show the evolution of classes of sounds. For example, the possible syllable shapes of Mandarin can be abstracted as ranging from /V/ (an atonic vowel) to /CGVNᵀ/ (a consonant-glide-vowel-nasal syllable with tone), and word-final devoicing may be schematized as C → C̥/_#. In speech pathology, capital letters represent indeterminate sounds, and may be superscripted to indicate they are weakly articulated: e.g. [ᴰ] is a weak indeterminate alveolar, [ᴷ] a weak indeterminate velar.[93]
There is a degree of variation between authors as to the capital letters used, but ⟨C⟩ for {consonant}, ⟨V⟩ for {vowel} and ⟨N⟩ for {nasal} are ubiquitous. Other common conventions are ⟨T⟩ for {tone/accent} (tonicity), ⟨P⟩ for {plosive}, ⟨F⟩ for {fricative}, ⟨S⟩ for {sibilant},[note 36] ⟨G⟩ for {glide/semivowel}, ⟨L⟩ for {lateral} or {liquid}, ⟨R⟩ for {rhotic} or {resonant/sonorant},[note 37] ⟨₵⟩ for {obstruent}, ⟨Ʞ⟩ for {click}, ⟨A, E, O, Ɨ, U⟩ for {open, front, back, close, rounded vowel}[note 38] and ⟨B, D, Ɉ, K, Q, Φ, H⟩ for {labial, alveolar, post-alveolar/palatal, velar, uvular, pharyngeal, glottal[note 39] consonant}, respectively, and ⟨X⟩ for {any sound}. The letters can be modified with IPA diacritics, for example ⟨Cʼ⟩ for {ejective}, ⟨Ƈ ⟩ for {implosive}, ⟨N͡C⟩ or ⟨ᴺC⟩ for {prenasalized consonant}, ⟨Ṽ⟩ for {nasal vowel}, ⟨CʰV́⟩ for {aspirated CV syllable with high tone}, ⟨S̬⟩ for {voiced sibilant}, ⟨N̥⟩ for {voiceless nasal}, ⟨P͡F⟩ or ⟨Pꟳ⟩ for {affricate}, ⟨Cʲ⟩ for {palatalized consonant} and ⟨D̪⟩ for {dental consonant}. ⟨H⟩, ⟨M⟩, ⟨L⟩ are also commonly used for high, mid and low tone, with ⟨LH⟩ for rising tone and ⟨HL⟩ for falling tone, rather than transcribing them overly precisely with IPA tone letters or with ambiguous digits.[note 40]
Typical examples of archiphonemic use of capital letters are ⟨I⟩ for the Turkish harmonic vowel set {i y ɯ u};[note 41] ⟨D⟩ for the conflated flapped middle consonant of American English writer and rider; ⟨N⟩ for the homorganic syllable-coda nasal of languages such as Spanish and Japanese (essentially equivalent to the wild-card usage of the letter); and ⟨R⟩ in cases where a phonemic trill /r/ and flap /ɾ/ are indeterminate, as in Spanish enrejar /eNreˈxaR/ (the n is homorganic and the first r is a trill but the second is variable).[94] Similar usage is found for phonemic analysis, where a language does not distinguish sounds that have separate letters in the IPA. For instance, Castillian Spanish has been analyzed as having phonemes /Θ/ and /S/, which surface as [θ] and [s] in voiceless environments and as [ð] and [z] in voiced environments (e.g. hazte /ˈaΘte/, → [ˈaθte], vs hazme /ˈaΘme/, → [ˈaðme]; or las manos /laS ˈmanoS/, → [lazˈmanos]).[95]
⟨V⟩, ⟨F⟩ and ⟨C⟩ have completely different meanings as Voice Quality Symbols, where they stand for "voice" (generally meaning secondary articulation, as in ⟨Ṽ⟩ "nasal voice", not phonetic voicing), "falsetto" and "creak". They may also take diacritics that indicate what kind of voice quality an utterance has, and may be used to extract a suprasegmental feature that occurs on all susceptible segments in a stretch of IPA. For instance, the transcription of Scottish Gaelic [kʷʰuˣʷt̪ʷs̟ʷ] 'cat' and [kʷʰʉˣʷt͜ʃʷ] 'cats' (Islay dialect) can be made more economical by extracting the suprasegmental labialization of the words: Vʷ[kʰuˣt̪s̟] and Vʷ[kʰʉˣt͜ʃ].[96] The usual wildcard X or C might be used instead of V so that the reader does not misinterpret ⟨Vʷ⟩ as meaning that only vowels are labialized (i.e. Xʷ[kʰuˣt̪s̟] for all segments labialized, Cʷ[kʰuˣt̪s̟] for all consonants labialized), or the carrier letter may be omitted altogether (e.g. ʷ[kʰuˣt̪s̟]). (See § Suprasegmentals for other transcription conventions.)
Segments without letters
The blank cells on the IPA chart can be filled without much difficulty if the need arises. The expected retroflex letter forms have appeared in the literature for the retroflex implosive ⟨ᶑ ⟩, the retroflex lateral flap ⟨𝼈 ⟩ and the retroflex clicks ⟨𝼊 ⟩; the first is mentioned in the IPA Handbook and the IPA requested Unicode support for superscript variants of all three. The missing voiceless lateral fricatives are provided for by the extIPA. The epiglottal trill is arguably covered by the generally trilled epiglottal "fricatives" ⟨ʜ ʢ⟩. Labiodental plosives ⟨ȹ ȸ⟩ appear in some old Bantuist texts. Ad hoc near-close central vowels ⟨ᵻ ᵿ⟩ are used in some descriptions of English. Diacritics can duplicate some of these; ⟨p̪ b̪⟩ are now universal for labiodental plosives, ⟨ɪ̈ ʊ̈⟩ are common for the central vowels and ⟨ɭ̆ ⟩ is occasionally seen for the lateral flap. Diacritics are able to fill in most of the remainder of the charts.[97] If a sound cannot be transcribed, an asterisk ⟨*⟩ may be used, either as a letter or as a diacritic (as in ⟨k*⟩ sometimes seen for the Korean "fortis" velar).
Consonants
Representations of consonant sounds outside of the core set are created by adding diacritics to letters with similar sound values. The Spanish bilabial and dental approximants are commonly written as lowered fricatives, [β̞] and [ð̞] respectively.[note 42] Similarly, voiced lateral fricatives would be written as raised lateral approximants, [ɭ˔ ʎ̝ ʟ̝]; extIPA provides ⟨𝼅⟩ for the first of these. A few languages such as Banda have a bilabial flap as the preferred allophone of what is elsewhere a labiodental flap. It has been suggested that this be written with the labiodental flap letter and the advanced diacritic, [ⱱ̟].[98] Similarly, a labiodental trill would be written [ʙ̪] (bilabial trill and the dental sign), and labiodental stops [p̪ b̪] rather than with the ad hoc letters sometimes found in the literature. Other taps can be written as extra-short plosives or laterals, e.g. [ ɟ̆ ɢ̆ ʟ̆], though in some cases the diacritic would need to be written below the letter. A retroflex trill can be written as a retracted [r̠], just as non-subapical retroflex fricatives sometimes are. The remaining consonants – the uvular laterals ([ʟ̠] etc.) and the palatal trill – while not strictly impossible, are very difficult to pronounce and are unlikely to occur even as allophones in the world's languages.
Vowels
The vowels are similarly manageable by using diacritics for raising, lowering, fronting, backing, centering, and mid-centering.[99] For example, the unrounded equivalent of [ʊ] can be transcribed as mid-centered [ɯ̽], and the rounded equivalent of [æ] as raised [ɶ̝] or lowered [œ̞] (though for those who conceive of vowel space as a triangle, simple [ɶ] already is the rounded equivalent of [æ]). True mid vowels are lowered [e̞ ø̞ ɘ̞ ɵ̞ ɤ̞ o̞] or raised [ɛ̝ œ̝ ɜ̝ ɞ̝ ʌ̝ ɔ̝], while centered [ɪ̈ ʊ̈] and [ä] (or, less commonly, [ɑ̈]) are near-close and open central vowels, respectively. The only known vowels that cannot be represented in this scheme are vowels with unexpected roundedness, which would require a dedicated diacritic, such as protruded ⟨ʏʷ⟩ and compressed ⟨uᵝ⟩ (or protruded ⟨ɪʷ⟩ and compressed ⟨ɯᶹ⟩).
Symbol names
An IPA symbol is often distinguished from the sound it is intended to represent, since there is not necessarily a one-to-one correspondence between letter and sound in broad transcription, making articulatory descriptions such as "mid front rounded vowel" or "voiced velar stop" unreliable. While the Handbook of the International Phonetic Association states that no official names exist for its symbols, it admits the presence of one or two common names for each.[100] The symbols also have nonce names in the Unicode standard. In many cases, the names in Unicode and the IPA Handbook differ. For example, the Handbook calls ⟨ɛ⟩ "epsilon", while Unicode calls it "small letter open e".
The traditional names of the Latin and Greek letters are usually used for unmodified letters.[note 43] Letters which are not directly derived from these alphabets, such as ⟨ʕ⟩, may have a variety of names, sometimes based on the appearance of the symbol or on the sound that it represents. In Unicode, some of the letters of Greek origin have Latin forms for use in IPA; the others use the characters from the Greek block.
For diacritics, there are two methods of naming. For traditional diacritics, the IPA notes the name in a well known language; for example, ⟨é⟩ is "e-acute", based on the name of the diacritic in English and French. Non-traditional diacritics are often named after objects they resemble, so ⟨d̪⟩ is called "d-bridge".
Geoffrey Pullum and William Ladusaw list a variety of names in use for IPA symbols, both current and retired, in their Phonetic Symbol Guide; many of these found their way into Unicode.[9]
Computer support
Unicode
Unicode supports nearly all of the IPA alphabet. Apart from basic Latin and Greek and general punctuation, the primary blocks are IPA Extensions, Spacing Modifier Letters and Combining Diacritical Marks, with lesser support from Phonetic Extensions, Phonetic Extensions Supplement, Combining Diacritical Marks Supplement, and scattered characters elsewhere. The extended IPA is supported primarily by those blocks and Latin Extended-G.
IPA numbers
After the Kiel Convention in 1989, most IPA symbols were assigned an identifying number to prevent confusion between similar characters during the printing of manuscripts. The codes were never much used and have been superseded by Unicode.[101]
Typefaces

Many typefaces have support for IPA characters, but good diacritic rendering remains rare.[102] Web browsers generally do not need any configuration to display IPA characters, provided that a typeface capable of doing so is available to the operating system.
System fonts
The ubiquitous Arial and Times New Roman fonts include IPA characters, but they are neither complete (especially Arial) nor render diacritics properly. The basic Latin Noto fonts are better, only failing with the more obscure characters. The proprietary Calibri font, which is the default font of Microsoft Office, has nearly complete IPA support with good diacritic rendering.
| Font | Sample | Comments |
|---|---|---|
| Times New Roman | ⟨˨˦˧꜒꜔꜓k͜𝼄a͎̽᷅ꟸ⟩ | The tone letters join properly, but the tie-bar and diacritics are displaced, and the diacritics overstrike each other rather than stacking |
Other commercial fonts
Brill has good IPA support. It is a commercial font but freely available for non-commercial use.[103]
Free fonts
Typefaces that provide nearly full IPA support and properly render diacritics include Gentium Plus, Charis SIL, Doulos SIL, and Andika. In addition to the support found in other fonts, these fonts support the full range of old-style (pre-Kiel) staveless tone letters, which do not have dedicated Unicode support, through an option to suppress the stave of the Chao tone letters.
ASCII and keyboard transliterations
Several systems have been developed that map the IPA symbols to ASCII characters. Notable systems include SAMPA and X-SAMPA. The usage of mapping systems in on-line text has to some extent been adopted in the context input methods, allowing convenient keying of IPA characters that would be otherwise unavailable on standard keyboard layouts.
IETF language tags
IETF language tags have registered fonipa as a variant subtag identifying text as written in IPA.[104] Thus, an IPA transcription of English could be tagged as en-fonipa. For the use of IPA without attribution to a concrete language, und-fonipa is available.
Computer input using on-screen keyboard
Online IPA keyboard utilities are available, though none of them cover the complete range of IPA symbols and diacritics.[note 44] In April 2019, Google's Gboard for Android added an IPA keyboard to its platform.[105][106] For iOS there are multiple free keyboard layouts available, e.g. "IPA Phonetic Keyboard".[107]
See also
- Afroasiatic phonetic notation
- Americanist phonetic notation – Phonetic alphabet developed in the 1880s
- Arabic International Phonetic Alphabet – System of phonetic transcription to adapt the International Phonetic Alphabet to the Arabic script
- Articulatory phonetics – A branch of linguistics studying how humans make sounds
- Case variants of IPA letters – International Phonetic Alphabet variants
- Cursive forms of the International Phonetic Alphabet – Deprecated cursive forms of IPA symbols
- Extensions to the International Phonetic Alphabet – Disordered speech additions to the phonetic alphabet
- Index of phonetics articles
- International Alphabet of Sanskrit Transliteration – Transliteration scheme for Indic scripts
- International Phonetic Alphabet chart for English dialects
- List of international common standards
- Luciano Canepari – Italian linguist
- Phonetic symbols in Unicode – Representation of phonetic symbols in the Unicode Standard
- RFE Phonetic Alphabet
- SAMPA – Computer-readable phonetic script
- Semyon Novgorodov – Yakut politician and linguist – inventor of IPA-based Yakut scripts
- TIPA provides IPA support for LaTeX
- UAI phonetic alphabet
- Uralic Phonetic Alphabet – Phonetic alphabet for Uralic languages
- Voice Quality Symbols – Set of phonetic symbols used for voice quality, such as to transcribe disordered speech
- X-SAMPA – Remapping of the IPA into ASCII
Notes
- The inverted bridge under the ⟨t̺ʰ⟩ specifies it as apical (pronounced with the tip of the tongue), and the superscript h shows that it is aspirated (breathy). Both these qualities cause the English /t/ to sound different from the French or Spanish /t/, which is a laminal (pronounced with the blade of the tongue) and unaspirated [t̻]. [t̺ʰ] and [t̻] are thus two different, though similar, sounds.
- "Originally, the aim was to make available a set of phonetic symbols which would be given different articulatory values, if necessary, in different languages." (International Phonetic Association, Handbook, pp. 195–196)
- "From its earliest days [...] the International Phonetic Association has aimed to provide 'a separate sign for each distinctive sound; that is, for each sound which, being used instead of another, in the same language, can change the meaning of a word'." (International Phonetic Association, Handbook, p. 27)
- For instance, flaps and taps are two different kinds of articulation, but since no language has (yet) been found to make a distinction between, say, an alveolar flap and an alveolar tap, the IPA does not provide such sounds with dedicated letters. Instead, it provides a single letter (in this case, [ɾ]) for both. Strictly speaking, this makes the IPA a partially phonemic alphabet, not a purely phonetic one.
- This exception to the rules was made primarily to explain why the IPA does not make a dental–alveolar distinction, despite one being phonemic in hundreds of languages, including most of the continent of Australia. Americanist Phonetic Notation makes (or at least made) a distinction between apical ⟨t d s z n l⟩ and laminal ⟨τ δ ς ζ ν λ⟩, which is easily applicable to alveolar vs dental (when a language distinguishes apical alveolar from laminal dental, as in Australia), but despite several proposals to the Council, the IPA never voted to accept such a distinction.
- There are three basic tone diacritics and five basic tone letters, both sets of which may be compounded.
- "The non-roman letters of the International Phonetic Alphabet have been designed as far as possible to harmonize well with the roman letters. The Association does not recognize makeshift letters; It recognizes only letters which have been carefully cut so as to be in harmony with the other letters." (IPA 1949)
- Originally, [ʊ] was written as a small capital U. However, this was not easy to read, and so it was replaced with a turned small capital omega. In modern typefaces, it often has its own design, called a 'horseshoe'.
- Merriam-Webster dictionaries use backslashes \ ... \ to demarcate their in-house transcription system. This distinguishes their IPA-influenced system from true IPA, which is used between forward slashes in the Oxford English Dictionary.
- For example, the single and double pipe symbols are used for minor and major prosodic breaks. Although the Handbook specifies the prosodic symbols as "thick" vertical lines, which would be distinct from simple ASCII pipes (and similar to Dania transcription), this is optional and was intended to keep them distinct from the pipes used as click letters (JIPA 19.2, p. 75). The Handbook (p. 174) assigns them the Unicode encodings U+007C, which is the simple ASCII pipe symbol, and U+2016.
- The proper angle brackets in Unicode are the mathematical symbols (U+27E8 and U+27E9). Chevrons ‹...› (U+2039, U+203A) are sometimes substituted, as in Americanist phonetic notation, as are the less-than and greater-than signs <...> (U+003C, U+003E) found on ASCII keyboards.
- See "Illustrations of the IPA" in the IPA Handbook (1999) for individual languages which for example may use ⟨/c/⟩ as a phonemic symbol for what is phonetically realized as [tʃ], or superscript variants of IPA letters that are not officially defined.
- Monolingual Hebrew dictionaries use pronunciation respelling for words with unusual spelling; for example, the Even-Shoshan Dictionary respells תָּכְנִית as ⟨תּוֹכְנִית⟩ because the word uses the kamatz katan.
- For example, Sergey Ozhegov's dictionary adds [нэ́] in brackets to the French loan-word пенсне (pince-nez) to indicate that the final ⟨е⟩ does not iotate the preceding ⟨н⟩.
- They were moved "for presentational convenience [...] because of [their] rarity and the small number of types of sounds which are found there." (IPA Handbook, p 18)
- It is traditional to place the tie bar above the letters. It may be placed below to avoid overlap with ascenders or diacritic marks, or simply because it is more legible that way, as in Niesler, Louw, & Roux (2005). "Phonetic analysis of Afrikaans, English, Xhosa and Zulu using South African speech databases". Ajol.info. Retrieved 20 November 2012.
{{cite web}}: CS1 maint: multiple names: authors list (link) - The IPA Handbook variously defines the "linking" symbol as marking the "lack of a boundary" (p. 23) or "absence of a break" (p. 174), and gives French liaison and English linking r as examples. The illustration for Croatian uses it to tie atonic clitics to tonic words, with no resulting change in implied syllable structure. It is also sometimes used simply to indicate that the consonant ending one word forms a syllable with the vowel beginning the following word.
- The global rise and fall arrows come before the affected syllable or prosodic unit, like stress and upstep/downstep. This contrasts with the Chao tone letters (listed below), which most commonly come after. One will occasionally see a horizontal arrow ⟨→⟩ for global level pitch (only dropping due to downdrift), e.g. in Julie Barbour (2012) A Grammar of Neverver. Additionally, some fonts display the arrows as emoji by default, if ︎ is not appended.
- There is not a one-to-one correspondence between tone diacritics and tone letters. When pitch is transcribed with diacritics, the three pitches ⟨é ē è⟩ are taken as the basic levels and are called 'high', 'mid' and 'low'. Contour tones combine only these three and are called ⟨e᷇⟩ 'high-mid' etc. The more extreme pitches, which do not form contours, are ⟨e̋⟩ 'extra-high' and ⟨ȅ⟩ 'extra-low', using doubled diacritics. When transcribed with tone letters, however, combinations of all five levels are possible. Thus, ⟨e˥ e˧ e˩⟩ may be called 'high', 'mid' and 'low', with ⟨e˦ e˨⟩ being 'near-high' and 'near-low', analogous to descriptions of vowel height. In a three-level transcription, ⟨é ē è⟩ are identified with ⟨e˥ e˧ e˩⟩, but in a five-level transcription, ⟨e̋ ȅ⟩ are identified with ⟨e˥ e˩⟩ (JIPA 19.2: 76).
- Although any combination of tone diacritics is theoretically possible, such as ⟨e᪰⟩ for a falling–rising–falling tone, any other than those illustrated are vanishingly rare.
- Russian sources commonly use a wavy line like U+2E3E ⸾ WIGGLY VERTICAL LINE (approx. ⌇) for a less-than-minor break, such as the slight break in list intonation (e.g. the very slight break between digits in a telephone number).[63] A dotted line like U+2E3D ⸽ VERTICAL SIX DOTS or U+2999 ⦙ DOTTED FENCE is sometimes seen instead.
- Maddieson and others have noted that a phonemic/phonetic distinction should be handled by /slash/ or [bracket] delimiters. However, the reversed tone letters remain in use for tone sandhi.
- A work-around sometimes seen when a language has more than one rising or falling tone, and the author wishes to avoid the poorly legible diacritics ⟨e᷄, e᷅, e᷇, e᷆⟩ but does not wish to employ tone letters, is to restrict the generic rising ⟨ě⟩ and falling ⟨ê⟩ diacritics to the higher-pitched of the rising and falling tones, say /e˥˧/ and /e˧˥/, and to resurrect the retired (pre-Kiel) IPA subscript diacritics ⟨e̗⟩ and ⟨e̖⟩ for the lower-pitched rising and falling tones, say /e˩˧/ and /e˧˩/. When a language has either four or six level tones, the two middle tones are sometimes transcribed as high-mid ⟨e̍⟩ (non-standard) and low-mid ⟨ē⟩. Non-standard ⟨e̍⟩ is occasionally seen combined with acute and grave diacritcs or with the macron to distinguish contour tones that involve the higher of the two mid tone levels.
- The example has changed over the years. In the chart included in the 1999 IPA Handbook, it was [˦˥˦], and since the 2018 revision of the chart it has been [˧˦˨].
- Chao did not include tone shapes such as [˨˦˦], [˧˩˩], which rise or fall and then level off (or vice versa). Such tone shapes are, however, frequently encountered in the modern literature.
- In Chao's Sinological convention, a single tone letter ⟨˥⟩ is used for a high tone on a checked syllable, and a double tone letter ⟨˥˥⟩ for a high tone on an open syllable. Such redundant doubling is not used in the Handbook, where the tones of Cantonese [si˥] 'silk' and [sɪk˥] 'color' are transcribed the same way. If the author wishes to indicate a difference in phonetic or phonemic length, the IPA accomplishes that with the length marks ⟨◌̆ ◌ˑ ◌ː⟩ rather than through the tone letters.
- Sometimes the obsolete transcription ⟨kʻ⟩ (with a turned apostrophe) for weak aspiration vs. ⟨kʰ⟩ for strong aspiration is still seen.
- Superscript ⟨ç⟩ is composed of superscript c and a combining cedilla, which should display properly in a good font. Superscript c was specifically requested for this purpose in Unicode proposal L2/03-180.
- These two characters are essentially the same. U+02E4 ˤ MODIFIER LETTER SMALL REVERSED GLOTTAL STOP, (middle), is specifically a superscript variant of U+0295 ʕ LATIN LETTER PHARYNGEAL VOICED FRICATIVE, whereas U+02C1 ˁ MODIFIER LETTER REVERSED GLOTTAL STOP (right), is a reversed U+02C0 ˀ MODIFIER LETTER GLOTTAL STOP – which by its Unicode description should be the same letter. Both characters see use beyond the IPA alphabet, and fonts are inconsistent in whether they look different and what the difference is. There is no parallel IPA/para-IPA distinction for superscript glottal stop.
- In Microsoft fonts this character was erroneously designed as a superscript ⟨ꬸ⟩.
- U+A71D ⟨ꜝ⟩ and A71E ⟨ꜞ⟩ were adopted as the Africanist equivalents of the IPA characters ⟨ꜜ⟩ downstep and ⟨ꜛ⟩ upstep. The correspondence of U+A71D ⟨ꜝ⟩ to the IPA click letter ⟨ǃ⟩ is thus accidental. Coincidentally, U+A71E ⟨ꜞ⟩ serves as the superscript variant of the extIPA percussive consonant ⟨¡⟩; percussive letters do not otherwise have superscript variants in Unicode.
- Not to be confused with U+1D4C ⟨ᵌ⟩, which is superscript ᴈ (a turned rather than reversed ɛ).
- Not to be confused with U+1D46 ⟨ᵆ⟩, which is superscript turned æ.
- In this instance, the old IPA letter for [tʲ], ⟨ƫ⟩, has a superscript variant in Unicode, U+1DB5 ⟨ᶵ⟩, as does the lateral, U+1DDA ⟨ᶪ⟩, but that is not generally the case.
- The motivation for this may vary. Some authors find the tie bars displeasing but the lack of tie bars confusing (i.e. ⟨č⟩ for /t͡ʃ/ as distinct from /tʃ/), while others simply prefer to have one letter for each segmental phoneme in a language.[citation needed]
- As in Afrasianist phonetic notation. ⟨S⟩ is particularly ambiguous. It has been used for 'stop', 'fricative', 'sibilant', 'sonorant' and 'semivowel'. On the other hand, plosive/stop is frequently abbreviated ⟨P⟩, ⟨T⟩ or ⟨S⟩. The illustrations given here use, as much as possible, letters that are capital versions of members of the sets they stand for: IPA [n] is a nasal and ⟨N⟩ is any nasal; [p] is a plosive, [f] a fricative, [s] a sibilant, [l] both a lateral and a liquid, [r] both a rhotic and a resonant, and [ʞ] a click. ⟨¢⟩ is an obstruent in Americanist notation, where it stands for [ts]. An alternative wildcard for 'glide', ⟨J⟩, fits this pattern, but is much less common than ⟨G⟩ in English-language sources.
- At least in the notation of ⟨CRV-⟩ syllables, the ⟨R⟩ is understood to include liquids and glides but to exclude nasals, as in Bennett (2020: 115) 'Click Phonology', in Sands (ed.), Click Consonants, Brill
- {Close vowel} may instead be ⟨U⟩, and ⟨O⟩ may stand for {obstruent}.
- Or glottal~pharyngeal ⟨H⟩, as in Afrasianist phonetic notation
- Somewhat more precisely, ⟨LM⟩ and ⟨MH⟩ are sometimes used for low and high rising tones, and ⟨HM⟩, ⟨ML⟩ for high and low falling tones; occasionally ⟨R⟩ for 'rising' or ⟨F⟩ for 'falling' is also seen.
- For other Turkic languages, ⟨I⟩ may be restricted to {ɯ i} (that is, to ı i), ⟨U⟩ to u ü, ⟨A⟩ to a e/ä, etc.
- Dedicated letters have been proposed, such as rotated ⟨β⟩ and ⟨ð⟩, reversed ⟨β⟩ and ⟨ð⟩, or small-capital ⟨б⟩ and ⟨ᴆ⟩. Ball, Rahilly & Lowry (2017) Phonetics for speech pathology, 3rd edition, Equinox, Sheffield.
- For example, the IPA Handbook lists ⟨p⟩ as "lower-case P" and ⟨χ⟩ as "chi." (International Phonetic Association, Handbook, p. 171)
- Online IPA keyboard utilities include the IPA 2018 i-charts hosted by the IPA, IPA character picker 27 at GitHub, Type IPA phonetic symbols at TypeIt.org, and an IPA Chart keyboard at GitHub.
References
- International Phonetic Association (IPA), Handbook.
- MacMahon, Michael K. C. (1996). "Phonetic Notation". In P. T. Daniels; W. Bright (eds.). The World's Writing Systems. New York: Oxford University Press. pp. 821–846. ISBN 0-19-507993-0.
- Wall, Joan (1989). International Phonetic Alphabet for Singers: A Manual for English and Foreign Language Diction. Pst. ISBN 1-877761-50-8.
- "IPA: Alphabet". Langsci.ucl.ac.uk. Archived from the original on 10 October 2012. Retrieved 20 November 2012.
- "Full IPA Chart". International Phonetic Association. Retrieved 24 April 2017.
- International Phonetic Association, Handbook, pp. 194–196
- Passy, Paul (1888). "Our revised alphabet". The Phonetic Teacher: 57–60.
- IPA in the Encyclopædia Britannica
- Pullum and Ladusaw, Phonetic Symbol Guide, pp. 152, 209
- Nicolaidis, Katerina (September 2005). "Approval of New IPA Sound: The Labiodental Flap". International Phonetic Association. Archived from the original on 2 September 2006. Retrieved 17 September 2006.
- International Phonetic Association, Handbook, p. 186
- Handbook, International Phonetic Association, p. 196,
The new letters should be suggestive of the sounds they represent, by their resemblance to the old ones.
. - Cf. the notes at the Unicode IPA EXTENSIONS code chart as well as blogs by Michael Everson Archived 10 October 2017 at the Wayback Machine and John Wells here and here.
- IPA Handbook p. 175
- IPA Handbook p. 176
- IPA Handbook p. 191
- IPA (1999) Handbook, p 188, 192
- IPA (1999) Handbook, p 176, 192
- Duckworth et al. (1990) Extensions to the International Phonetic Alphabet for the transcription of atypical speech. Clinical Linguistics & Phonetics 4: 4: 278.
- Basbøll (2005) The Phonology of Danish pp. 45, 59
- Karlsson & Sullivan (2005) /sP/ consonant clusters in Swedish: Acoustic measurements of phonological development
- Richard Sproat (2000) A Computational Theory of Writing Systems. Cambridge University Press. Page 26.
- Barry Heselwood (2013) Phonetic Transcription in Theory and Practice. Edinburgh University Press. Page 8 ff, 29 ff.
- Paul Tench (2011) Transcribing the Sound of English. Cambridge University Press. Page 61.
- Gibbon, Dafydd; Moore, Roger; Winski, Richard (1998). Handbook of Standards and Resources for Spoken Language Systems: Spoken language characterisation. Berlin; New York: Walter de Gruyter. p. 61. ISBN 9783110157345.
- Ball, Martin J.; Lowry, Orla M. (2001). "Transcribing Disordered Speech". Methods in Clinical Phonetics. London: Whurr. p. 80. doi:10.1002/9780470777879.ch3. ISBN 9781861561848. S2CID 58518097.
- International Phonetic Association 1999, p. 31.
- Esling, John H. (2010). "Phonetic Notation". In Hardcastle, William J.; Laver, John; Gibbon, Fiona E. (eds.). The Handbook of Phonetic Sciences (2nd ed.). Wiley-Blackwell. pp. 678–702. doi:10.1002/9781444317251.ch18. ISBN 978-1-4051-4590-9. pp. 688, 693.
- Martin J. Ball; Joan Rahilly (August 2011). "The symbolization of central approximants in the IPA". Journal of the International Phonetic Association. Cambridge Journals Online. 41 (2): 231–237. doi:10.1017/s0025100311000107. S2CID 144408497.
- "Cambridge Journals Online – Journal of the International Phonetic Association Vol. 39 Iss. 02". Journals.cambridge.org. 23 October 2012. Retrieved 20 November 2012.
- "IPA: About us". Langsci.ucl.ac.uk. Archived from the original on 10 October 2012. Retrieved 20 November 2012.
- "IPA: Statutes". Langsci.ucl.ac.uk. Archived from the original on 10 October 2012. Retrieved 20 November 2012.
- "IPA: News". Langsci.ucl.ac.uk. Archived from the original on 11 November 2012. Retrieved 20 November 2012.
- "IPA: News". Langsci.ucl.ac.uk. Archived from the original on 11 November 2012. Retrieved 20 November 2012.
- Kirk Miller & Michael Ashby, L2/20-252R Unicode request for IPA modifier-letters (a), pulmonic
- Sally Thomason (2 January 2008). "Why I Don't Love the International Phonetic Alphabet". Language Log.
- "Phonetics". Cambridge Dictionaries Online. 2002. Archived from the original on 17 August 2011. Retrieved 11 March 2007.
- "Merriam-Webster Online Pronunciation Symbols". Archived from the original on 1 June 2007. Retrieved 4 June 2007.
Agnes, Michael (1999). Webster's New World College Dictionary. New York: Macmillan. xxiii. ISBN 0-02-863119-6.
Pronunciation respelling for English has detailed comparisons. - (in Czech) Fronek, J. (2006). Velký anglicko-český slovník (in Czech). Praha: Leda. ISBN 80-7335-022-X.
In accordance with long-established Czech lexicographical tradition, a modified version of the International Phonetic Alphabet (IPA) is adopted in which letters of the Czech alphabet are employed.
- Principles of the International Phonetic Association, 1949:17.
- Severens, Sara E. (2017). "The Effects of the International Phonetic Alphabet in Singing". Student Scholar Showcase.
- "Nico Castel's Complete Libretti Series". Castel Opera Arts. Archived from the original on 24 July 2011. Retrieved 29 September 2008.
- Cheek, Timothy (2001). Singing in Czech. The Scarecrow Press. p. 392. ISBN 978-0-8108-4003-4. Archived from the original on 7 October 2011. Retrieved 25 January 2020.
- Zimmer, Benjamin (14 May 2008). "Operatic IPA and the Visual Thesaurus". Language Log. University of Pennsylvania. Retrieved 29 September 2009.
- "Segments can usefully be divided into two major categories, consonants and vowels." (International Phonetic Association, Handbook, p. 3)
- International Phonetic Association, Handbook, p. 6.
- Fromkin, Victoria; Rodman, Robert (1998) [1974]. An Introduction to Language (6th ed.). Fort Worth, TX: Harcourt Brace College Publishers. ISBN 0-03-018682-X.
- Ladefoged and Maddieson, 1996, Sounds of the World's Languages, §2.1.
- "A symbol such as [β], shown on the chart in the position for a voiced bilabial fricative, can also be used to represent a voiced bilabial approximant if needed." (Handbook, p.9)
- Ladefoged and Maddieson, 1996, Sounds of the World's Languages, §9.3.
- Esling (2010), pp. 688–9.
- Amanda L. Miller et al., "Differences in airstream and posterior place of articulation among Nǀuu lingual stops". Submitted to the Journal of the International Phonetic Association. Retrieved 27 May 2007.
- Ladefoged, Peter; Ian Maddieson (1996). The sounds of the world's languages. Oxford: Blackwell. pp. 329–330. ISBN 0-631-19815-6.
- International Phonetic Association, Handbook, p. 10.
- International Phonetic Association, Handbook, pp. 14–15.
- 'Further report on the 1989 Kiel Convention', Journal of the International Phonetic Association 20:2 (December 1990), p. 23.
- International Phonetic Association, Handbook, p. 13.
- Cf. the /ʷ.../ and /ʲ.../ transcriptions in Eszter Ernst-Kurdi (2017) The Phonology of Mada, SIL Yaoundé.
- E.g. Aaron Dolgopolsky (2013) Indo-European Dictionary with Nostratic Etymologies.
- P.J. Roach, Report on the 1989 Kiel Convention, Journal of the International Phonetic Association, Vol. 19, No. 2 (December 1989), p. 75–76
- Esling (2010), p. 691.
- For example, "Balearic". Merriam-Webster Dictionary..
- Ž.V. Ganiev (2012) Sovremennyj ruskij jazyk. Flinta/Nauka.
- Nicholas Evans (1995) A Grammar of Kayardild. Mouton de Gruyter.
- Ian Maddieson (December 1990) The transcription of tone in the IPA, JIPA 20.2, p. 31.
- Barry Heselwood (2013) Phonetic Transcription in Theory and Practice. Edinburgh University Press. Page 7.
- Chao, Yuen-Ren (1930), "ə sistim əv "toun-letəz"" [A system of "tone-letters"], Le Maître Phonétique, 30: 24–27, JSTOR 44704341
- See for example Pe Maung Tin [-phe -maʊ̃ -tɪ̃ː] (1924) bɜˑmiːz. Le Maître Phonétique, vol. 2 (39), no. 5, pp. 4–5, where five pitch levels are distinguished
- Handbook, p. 14.
- Kelly & Local (1989) Doing Phonology, Manchester University Press.
- Bloomfield (1933) Language p. 91
- Passy, 1958, Conversations françaises en transcription phonétique. 2nd ed.
- Yuen Ren Chao (1968) Language and Symbolic Systems, p. xxiii
- Geoffrey Barker (2005) Intonation Patterns in Tyrolean German, p. 11.
- Ladefoged, Peter; Maddieson, Ian (1996). The Sounds of the World's Languages. Oxford: Blackwell. p. 314. ISBN 978-0-631-19815-4.
- Peter Ladefoged (1971) Preliminaries of Linguistic Phonetics, p. 35.
- Fallon (2013) The Synchronic and Diachronic Phonology of Ejectives, p. 267
- Heselwood (2013) Phonetic Transcription in Theory and Practice, p. 233.
- E.g. in Laver (1994) Principles of Phonetics, pp. 559–560
- Hein van der Voort (2005) 'Kwaza in a Comparative Perspective', IJAL 71:4.
- John Esling (2010) "Phonetic Notation", in Hardcastle, Laver & Gibbon (eds) The Handbook of Phonetic Sciences, 2nd ed., p 695.
- Ridouane, Rachid (August 2014). "Tashlhiyt Berber". Journal of the International Phonetic Association. 44 (2): 207–221. doi:10.1017/S0025100313000388. S2CID 232344118. Retrieved 20 November 2021.
- Alderete, John; Jebbour, Abdelkrim; Kachoub, Bouchra; Wilbee, Holly. "Tashlhiyt Berber grammar synopsis" (PDF). Simon Fraser University. Retrieved 20 November 2021.
- Kirk Miller & Michael Ashby, L2/20-253R Unicode request for IPA modifier letters (b), non-pulmonic.
- Kirk Miller & Martin Ball, L2/20-116R Expansion of the extIPA and VoQS.
- "John Wells's phonetic blog". Phonetic-blog.blogspot.com. 9 September 2009. Retrieved 18 October 2010.
- "At the 1989 Kiel Convention of the IPA, a sub-group was established to draw up recommendations for the transcription of disordered speech." ("Extensions to the IPA: An ExtIPA Chart" in International Phonetic Association, Handbook, p. 186.)
- PRDS Group (1983). The Phonetic Representation of Disordered Speech. London: The King's Fund.
- "Extensions to the IPA: An ExtIPA Chart" in International Phonetic Association, Handbook, pp. 186–187.
- e.g. Alan Kaye (2007) Morphologies of Asia and Africa. Eisenbrauns.
- Campbell, Lyle (2013). Historical linguistics: an introduction (3. ed.). Edinburgh: Edinburgh University Press. pp. xix. ISBN 9780262518499.
- Haynie, Bowern, Epps, Hill & McConvell (2014) Wanderwörter in languages of the Americas and Australia. Ampersand 1:1–18.
- Perry (2000) Phonological/phonetic assessment of an English-speaking adult with dysarthria
- Antonio Quilis (1997) Principios de fonología y fonética españolas, p. 65.
- Xavier Frías Conde (2001) Introducción a la fonología y fonética del español, p. 11–12. Ianua. Revista Philologica Romanica.
- Laver (1994) Principles of Phonetics, p. 374.
- "Diacritics may also be employed to create symbols for phonemes, thus reducing the need to create new letter shapes." (International Phonetic Association, Handbook, p. 27)
- Olson, Kenneth S.; Hajek, John (1999). "The phonetic status of the labial flap". Journal of the International Phonetic Association. 29 (2): 101–114. doi:10.1017/s0025100300006484. S2CID 14438770.
- "The diacritics...can be used to modify the lip or tongue position implied by a vowel symbol." (International Phonetic Association, Handbook, p. 16)
- "...the International Phonetic Association has never officially approved a set of names..." (International Phonetic Association, Handbook, p. 31)
- A chart of the numbers for the most common IPA symbols can be found on the IPA website.IPA number chart
- "Es gilt das gesprochene Wort: Schriftarten für IPA-Transkriptionen" (in German). 16 March 2014. Retrieved 18 August 2022.
- "Brill Typeface". Retrieved 18 August 2022.
- "Language Subtag Registry". IANA. 5 March 2021. Retrieved 30 April 2021.
- "Gboard updated with 63 new languages, including IPA (not the beer)". Android Police. 18 April 2019. Retrieved 28 April 2019.
- "Set up Gboard – Android – Gboard Help". support.google.com. Retrieved 28 April 2019.
- "IPA Phonetic Keyboard". App Store. Retrieved 8 December 2020.
Further reading
- Ball, Martin J.; John H. Esling; B. Craig Dickson (1995). "The VoQS system for the transcription of voice quality". Journal of the International Phonetic Association. 25 (2): 71–80. doi:10.1017/S0025100300005181. S2CID 145791575.
- Duckworth, M.; G. Allen; M.J. Ball (December 1990). "Extensions to the International Phonetic Alphabet for the transcription of atypical speech". Clinical Linguistics and Phonetics. 4 (4): 273–280. doi:10.3109/02699209008985489.
- Hill, Kenneth C.; Pullum, Geoffrey K.; Ladusaw, William (March 1988). "Review of Phonetic Symbol Guide by G. K. Pullum & W. Ladusaw". Language. 64 (1): 143–144. doi:10.2307/414792. JSTOR 414792.
- International Phonetic Association (1989). "Report on the 1989 Kiel convention". Journal of the International Phonetic Association. 19 (2): 67–80. doi:10.1017/s0025100300003868. S2CID 249412330.
- International Phonetic Association (1999). Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet. Cambridge: Cambridge University Press. ISBN 0-521-65236-7. (hb); ISBN 0-521-63751-1 (pb).
- Jones, Daniel (1988). English pronouncing dictionary (revised 14th ed.). London: Dent. ISBN 0-521-86230-2. OCLC 18415701.
- Ladefoged, Peter (September 1990). "The revised International Phonetic Alphabet". Language. 66 (3): 550–552. doi:10.2307/414611. JSTOR 414611.
- Ladefoged, Peter; Morris Halle (September 1988). "Some major features of the International Phonetic Alphabet". Language. 64 (3): 577–582. doi:10.2307/414533. JSTOR 414533.
- Laver, John (1994). Principles of Phonetics. New York: Cambridge University Press. ISBN 0-521-45031-4. (hb); ISBN 0-521-45655-X (pb).
- Pullum, Geoffrey K.; William A. Ladusaw (1986). Phonetic Symbol Guide. Chicago: University of Chicago Press. ISBN 0-226-68532-2.
- Skinner, Edith; Timothy Monich; Lilene Mansell (1990). Speak with Distinction. New York: Applause Theatre Book Publishers. ISBN 1-55783-047-9.
- Fromkin, Victoria; Rodman, Robert; Hyams, Nina (2011). An Introduction to Language (9th ed.). Boston: Wadsworth, Cenage Learning. pp. 233–234. ISBN 978-1-4282-6392-5.
External links
International Phonetic Alphabet (chart) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Authority control: National libraries |
|---|
На других языках
- [en] International Phonetic Alphabet
[ru] Международный фонетический алфавит
Междунаро́дный фонети́ческий алфави́т (сокр. МФА) (англ. International Phonetic Alphabet, сокр. IPA; фр. Alphabet phonétique international, сокр. API) — система знаков для записи транскрипции на основе латинского алфавита. Разработан и поддерживается Международной фонетической ассоциацией[2]. МФА используется преподавателями иностранных языков и студентами, лингвистами, логопедами, певцами, актёрами, лексикографами и переводчиками[3][4].Другой контент может иметь иную лицензию. Перед использованием материалов сайта WikiSort.org внимательно изучите правила лицензирования конкретных элементов наполнения сайта.
WikiSort.org - проект по пересортировке и дополнению контента Википедии