lingvo.wikisort.org - Alphabet
The Latin script, also known as Roman script, is an alphabetic writing system based on the letters of the classical Latin alphabet, derived from a form of the Greek alphabet which was in use in the ancient Greek city of Cumae, in southern Italy (Magna Grecia). It was adopted by the Etruscans and subsequently by the Romans. Several Latin-script alphabets exist, which differ in graphemes, collation and phonetic values from the classical Latin alphabet.
This article includes a list of general references, but it lacks sufficient corresponding inline citations. (October 2017) |
| Latin Roman | |
|---|---|
 | |
| Script type | Alphabet
|
Time period | c. 700 BC – present |
| Direction | left-to-right |
| Languages |
Official script in: 132 sovereign states
Co-official script in: 15 sovereign states
|
| Related scripts | |
Parent systems | Egyptian hieroglyphs
|
Child systems |
|
Sister systems | |
| ISO 15924 | |
| ISO 15924 | Latn (215), Latin |
| Unicode | |
Unicode alias | Latin |
Unicode range | See Latin characters in Unicode |
The Latin script is the basis of the International Phonetic Alphabet, and the 26 most widespread letters are the letters contained in the ISO basic Latin alphabet.
Latin script is the basis for the largest number of alphabets of any writing system[1] and is the most widely adopted writing system in the world. Latin script is used as the standard method of writing for most Western and Central, and some Eastern, European languages as well as many languages in other parts of the world.
Name
The script is either called Latin script or Roman script, in reference to its origin in ancient Rome (though some of the capital letters are Greek in origin). In the context of transliteration, the term "romanization" (British English: "romanisation") is often found.[2][3] Unicode uses the term "Latin"[4] as does the International Organization for Standardization (ISO).[5]
The numeral system is called the Roman numeral system, and the collection of the elements is known as the Roman numerals. The numbers 1, 2, 3 ... are Latin/Roman script numbers for the Hindu–Arabic numeral system.
History
Old Italic alphabet
| Letters | 𐌀 | 𐌁 | 𐌂 | 𐌃 | 𐌄 | 𐌅 | 𐌆 | 𐌇 | 𐌈 | 𐌉 | 𐌊 | 𐌋 | 𐌌 | 𐌍 | 𐌎 | 𐌏 | 𐌐 | 𐌑 | 𐌒 | 𐌓 | 𐌔 | 𐌕 | 𐌖 | 𐌗 | 𐌘 | 𐌙 | 𐌚 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Transliteration | A | B | C | D | E | V | Z | H | Θ | I | K | L | M | N | E | O | P | Ś | Q | R | S | T | Y | X | Φ | Ψ | F |
Archaic Latin alphabet
| As Old Italic | 𐌀 | 𐌁 | 𐌂 | 𐌃 | 𐌄 | 𐌅 | 𐌆 | 𐌇 | 𐌉 | 𐌊 | 𐌋 | 𐌌 | 𐌍 | 𐌏 | 𐌐 | 𐌒 | 𐌓 | 𐌔 | 𐌕 | 𐌖 | 𐌗 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| As Latin | A | B | C | D | E | F | Z | H | I | K | L | M | N | O | P | Q | R | S | T | V | X |
The letter ⟨C⟩ was the western form of the Greek gamma, but it was used for the sounds /ɡ/ and /k/ alike, possibly under the influence of Etruscan, which might have lacked any voiced plosives. Later, probably during the 3rd century BC, the letter ⟨Z⟩ – unneeded to write Latin properly – was replaced with the new letter ⟨G⟩, a ⟨C⟩ modified with a small horizontal stroke, which took its place in the alphabet. From then on, ⟨G⟩ represented the voiced plosive /ɡ/, while ⟨C⟩ was generally reserved for the voiceless plosive /k/. The letter ⟨K⟩ was used only rarely, in a small number of words such as Kalendae, often interchangeably with ⟨C⟩.
Classical Latin alphabet
After the Roman conquest of Greece in the 1st century BC, Latin adopted the Greek words
⟨Y⟩ and ⟨Z⟩ (or readopted, in the latter case) to write Greek loanwords, placing them at the end of the alphabet. An attempt by the emperor Claudius to introduce three additional letters did not last. Thus it was during the classical Latin period that the Latin alphabet contained 23 letters:Italic text
| Letter | A | B | C | D | E | F | G | H | I | K | L | M | N | O | P | Q | R | S | T | V | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Latin name (majus) | á | bé | cé | dé | é | ef | gé | há | ꟾ | ká | el | em | en | ó | pé | qv́ | er | es | té | v́ | ix | ꟾ graeca | zéta |
| Latin name | ā | bē | cē | dē | ē | ef | gē | hā | ī | kā | el | em | en | ō | pē | qū | er | es | tē | ū | ix | ī Graeca | zēta |
| Latin pronunciation (IPA) | aː | beː | keː | deː | eː | ɛf | ɡeː | haː | iː | kaː | ɛl | ɛm | ɛn | oː | peː | kuː | ɛr | ɛs | teː | uː | iks | iː ˈɡraeka | ˈdzeːta |
Medieval and later developments


It was not until the Middle Ages that the letter ⟨W⟩ (originally a ligature of two ⟨V⟩s) was added to the Latin alphabet, to represent sounds from the Germanic languages which did not exist in medieval Latin, and only after the Renaissance did the convention of treating ⟨I⟩ and ⟨U⟩ as vowels, and ⟨J⟩ and ⟨V⟩ as consonants, become established. Prior to that, the former had been merely allographs of the latter.[citation needed]
With the fragmentation of political power, the style of writing changed and varied greatly throughout the Middle Ages, even after the invention of the printing press. Early deviations from the classical forms were the uncial script, a development of the Old Roman cursive, and various so-called minuscule scripts that developed from New Roman cursive, of which the insular script developed by Irish literati & derivations of this, such as Carolingian minuscule were the most influential, introducing the lower case forms of the letters, as well as other writing conventions that have since become standard.
The languages that use the Latin script generally use capital letters to begin paragraphs and sentences and proper nouns. The rules for capitalization have changed over time, and different languages have varied in their rules for capitalization. Old English, for example, was rarely written with even proper nouns capitalized, whereas Modern English writers and printers of the 17th and 18th century frequently capitalized most and sometimes all nouns[6] – e.g. in the preamble and all of the United States Constitution – a practice still systematically used in Modern German.
ISO basic Latin alphabet
| Uppercase Latin alphabet | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lowercase Latin alphabet | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
The use of the letters I and V for both consonants and vowels proved inconvenient as the Latin alphabet was adapted to Germanic and Romance languages. W originated as a doubled V (VV) used to represent the Voiced labial–velar approximant /w/ found in Old English as early as the 7th century. It came into common use in the later 11th century, replacing the letter wynn ⟨Ƿ ƿ⟩, which had been used for the same sound. In the Romance languages, the minuscule form of V was a rounded u; from this was derived a rounded capital U for the vowel in the 16th century, while a new, pointed minuscule v was derived from V for the consonant. In the case of I, a word-final swash form, j, came to be used for the consonant, with the un-swashed form restricted to vowel use. Such conventions were erratic for centuries. J was introduced into English for the consonant in the 17th century (it had been rare as a vowel), but it was not universally considered a distinct letter in the alphabetic order until the 19th century.
By the 1960s, it became apparent to the computer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin alphabet in their (ISO/IEC 646) standard. To achieve widespread acceptance, this encapsulation was based on popular usage. As the United States held a preeminent position in both industries during the 1960s, the standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 (uppercase and lowercase) letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin alphabet with extensions to handle other letters in other languages.
Spread
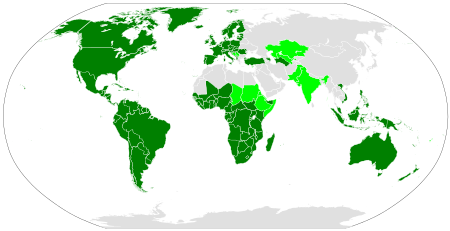
The Latin alphabet spread, along with Latin, from the Italian Peninsula to the lands surrounding the Mediterranean Sea with the expansion of the Roman Empire. The eastern half of the Empire, including Greece, Turkey, the Levant, and Egypt, continued to use Greek as a lingua franca, but Latin was widely spoken in the western half, and as the western Romance languages evolved out of Latin, they continued to use and adapt the Latin alphabet.
Middle Ages
With the spread of Western Christianity during the Middle Ages, the Latin alphabet was gradually adopted by the peoples of Northern Europe who spoke Celtic languages (displacing the Ogham alphabet) or Germanic languages (displacing earlier Runic alphabets) or Baltic languages, as well as by the speakers of several Uralic languages, most notably Hungarian, Finnish and Estonian.
The Latin script also came into use for writing the West Slavic languages and several South Slavic languages, as the people who spoke them adopted Roman Catholicism. The speakers of East Slavic languages generally adopted Cyrillic along with Orthodox Christianity. The Serbian language uses both scripts, with Cyrillic predominating in official communication and Latin elsewhere, as determined by the Law on Official Use of the Language and Alphabet.[7]
Since the 16th century
As late as 1500, the Latin script was limited primarily to the languages spoken in Western, Northern, and Central Europe. The Orthodox Christian Slavs of Eastern and Southeastern Europe mostly used Cyrillic, and the Greek alphabet was in use by Greek-speakers around the eastern Mediterranean. The Arabic script was widespread within Islam, both among Arabs and non-Arab nations like the Iranians, Indonesians, Malays, and Turkic peoples. Most of the rest of Asia used a variety of Brahmic alphabets or the Chinese script.
Through European colonization the Latin script has spread to the Americas, Oceania, parts of Asia, Africa, and the Pacific, in forms based on the Spanish, Portuguese, English, French, German and Dutch alphabets.
It is used for many Austronesian languages, including the languages of the Philippines and the Malaysian and Indonesian languages, replacing earlier Arabic and indigenous Brahmic alphabets. Latin letters served as the basis for the forms of the Cherokee syllabary developed by Sequoyah; however, the sound values are completely different.[citation needed]
Under Portuguese missionary influence, a Latin alphabet was devised for the Vietnamese language, which had previously used Chinese characters. The Latin-based alphabet replaced the Chinese characters in administration in the 19th century with French rule.
Since 19th century
In the late 19th century, the Romanians switched to the Latin alphabet, which they had used until the Council of Florence in 1439,[8] primarily because Romanian is a Romance language. The Romanians were predominantly Orthodox Christians, and their Church, increasingly influenced by Russia after the fall of Byzantine Greek Constantinople in 1453 and capture of the Greek Orthodox Patriarch, had begun promoting the Slavic Cyrillic.
Since 20th century
In 1928, as part of Mustafa Kemal Atatürk's reforms, the new Republic of Turkey adopted a Latin alphabet for the Turkish language, replacing a modified Arabic alphabet. Most of the Turkic-speaking peoples of the former USSR, including Tatars, Bashkirs, Azeri, Kazakh, Kyrgyz and others, had their writing systems replaced by the Latin-based Uniform Turkic alphabet in the 1930s; but, in the 1940s, all were replaced by Cyrillic.
After the collapse of the Soviet Union in 1991, three of the newly independent Turkic-speaking republics, Azerbaijan, Uzbekistan, Turkmenistan, as well as Romanian-speaking Moldova, officially adopted Latin alphabets for their languages. Kyrgyzstan, Iranian-speaking Tajikistan, and the breakaway region of Transnistria kept the Cyrillic alphabet, chiefly due to their close ties with Russia.
In the 1930s and 1940s, the majority of Kurds replaced the Arabic script with two Latin alphabets. Although only the official Kurdish government uses an Arabic alphabet for public documents, the Latin Kurdish alphabet remains widely used throughout the region by the majority of Kurdish-speakers.
In 1957, the People's Republic of China introduced a script reform to the Zhuang language, changing its orthography from Sawndip, a writing system based on Chinese, to a Latin script alphabet that used a mixture of Latin, Cyrillic, and IPA letters to represent both the phonemes and tones of the Zhuang language, without the use of diacritics. In 1982 this was further standardised to use only Latin script letters.
With the collapse of the Derg and subsequent end of decades of Amharic assimilation in 1991, various ethnic groups in Ethiopia dropped the Geʽez script, which was deemed unsuitable for languages outside of the Semitic branch.[9] In the following years the Kafa,[10] Oromo,[11] Sidama,[12] Somali,[12] and Wolaitta[12] languages switched to Latin while there is continued debate on whether to follow suit for the Hadiyya and Kambaata languages.[13]
21st century
On 15 September 1999 the authorities of Tatarstan, Russia, passed a law to make the Latin script a co-official writing system alongside Cyrillic for the Tatar language by 2011.[14] A year later, however, the Russian government overruled the law and banned Latinization on its territory.[15]
In 2015, the government of Kazakhstan announced that a Kazakh Latin alphabet would replace the Kazakh Cyrillic alphabet as the official writing system for the Kazakh language by 2025.[16] There are also talks about switching from the Cyrillic script to Latin in Ukraine,[17] Kyrgyzstan,[18][19] and Mongolia.[20] Mongolia, however, has since opted to revive the Mongolian script instead of switching to Latin.[21]
In October 2019, the organization National Representational Organization for Inuit in Canada (ITK) announced that they will introduce a unified writing system for the Inuit languages in the country. The writing system is based on the Latin alphabet and is modeled after the one used in the Greenlandic language.[22]
On 12 February 2021 the government of Uzbekistan announced it will finalize the transition from Cyrillic to Latin for the Uzbek language by 2023. Plans to switch to Latin originally began in 1993 but subsequently stalled and Cyrillic remained in widespread use.[23][24]
At present the Crimean Tatar language uses both Cyrillic and Latin. The use of Latin was originally approved by Crimean Tatar representatives after the Soviet Union's collapse[25] but was never implemented by the regional government. After Russia's annexation of Crimea in 2014 the Latin script was dropped entirely. Nevertheless Crimean Tatars outside of Crimea continue to use Latin and on 22 October 2021 the government of Ukraine approved a proposal endorsed by the Mejlis of the Crimean Tatar People to switch the Crimean Tatar language to Latin by 2025.[26]
In July 2020, 2.6 billion people (36% of the world population) use the Latin alphabet.[27]
International standards
By the 1960s, it became apparent to the computer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin alphabet in their (ISO/IEC 646) standard. To achieve widespread acceptance, this encapsulation was based on popular usage.
As the United States held a preeminent position in both industries during the 1960s, the standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 (uppercase and lowercase) letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin alphabet with extensions to handle other letters in other languages.
National standards
The DIN standard DIN 91379 specifies a subset of Unicode letters, special characters, and sequences of letters and diacritic signs to allow the correct representation of names and to simplify data exchange in Europe. This specification supports all official languages of European Union countries (thus also Greek and Cyrillic for Bulgarian) as well as the official languages of Iceland, Liechtenstein, Norway, and Switzerland, and also the German minority languages. To allow the transliteration of names in other writing systems to the Latin script according to the relevant ISO standards all necessary combinations of base letters and diacritic signs are provided.[28] Efforts are being made to further develop it into a European CEN standard.[29]
As used by various languages
In the course of its use, the Latin alphabet was adapted for use in new languages, sometimes representing phonemes not found in languages that were already written with the Roman characters. To represent these new sounds, extensions were therefore created, be it by adding diacritics to existing letters, by joining multiple letters together to make ligatures, by creating completely new forms, or by assigning a special function to pairs or triplets of letters. These new forms are given a place in the alphabet by defining an alphabetical order or collation sequence, which can vary with the particular language.
Letters
Some examples of new letters to the standard Latin alphabet are the Runic letters wynn ⟨Ƿ ƿ⟩ and thorn ⟨Þ þ⟩, and the letter eth ⟨Ð/ð⟩, which were added to the alphabet of Old English. Another Irish letter, the insular g, developed into yogh ⟨Ȝ ȝ⟩, used in Middle English. Wynn was later replaced with the new letter ⟨w⟩, eth and thorn with ⟨th⟩, and yogh with ⟨gh⟩. Although the four are no longer part of the English or Irish alphabets, eth and thorn are still used in the modern Icelandic alphabet, while eth is also used by the Faroese alphabet.
Some West, Central and Southern African languages use a few additional letters that have sound values similar to those of their equivalents in the IPA. For example, Adangme uses the letters ⟨Ɛ ɛ⟩ and ⟨Ɔ ɔ⟩, and Ga uses ⟨Ɛ ɛ⟩, ⟨Ŋ ŋ⟩ and ⟨Ɔ ɔ⟩. Hausa uses ⟨Ɓ ɓ⟩ and ⟨Ɗ ɗ⟩ for implosives, and ⟨Ƙ ƙ⟩ for an ejective. Africanists have standardized these into the African reference alphabet.
Dotted and dotless I — ⟨İ i⟩ and ⟨I ı⟩ — are two forms of the letter I used by the Turkish, Azerbaijani, and Kazakh alphabets.[30] The Azerbaijani language also has ⟨Ə ə⟩, which represents the near-open front unrounded vowel.
Multigraphs
A digraph is a pair of letters used to write one sound or a combination of sounds that does not correspond to the written letters in sequence. Examples are ⟨ch⟩, ⟨ng⟩, ⟨rh⟩, ⟨sh⟩, ⟨ph⟩, ⟨th⟩ in English, and ⟨ij⟩, ⟨ee⟩, ⟨ch⟩ and ⟨ei⟩ in Dutch. In Dutch the ⟨ij⟩ is capitalized as ⟨IJ⟩ or the ligature ⟨IJ⟩, but never as ⟨Ij⟩, and it often takes the appearance of a ligature ⟨ij⟩ very similar to the letter ⟨ÿ⟩ in handwriting.
A trigraph is made up of three letters, like the German ⟨sch⟩, the Breton ⟨c'h⟩ or the Milanese ⟨oeu⟩. In the orthographies of some languages, digraphs and trigraphs are regarded as independent letters of the alphabet in their own right. The capitalization of digraphs and trigraphs is language-dependent, as only the first letter may be capitalized, or all component letters simultaneously (even for words written in title case, where letters after the digraph or trigraph are left in lowercase).
Ligatures
A ligature is a fusion of two or more ordinary letters into a new glyph or character. Examples are ⟨Æ æ⟩ (from ⟨AE⟩, called "ash"), ⟨Œ œ⟩ (from ⟨OE⟩, sometimes called "oethel"), the abbreviation ⟨&⟩ (from Latin: et, lit. 'and', called "ampersand"), and ⟨ẞ ß⟩ (from ⟨ſʒ⟩ or ⟨ſs⟩, the archaic medial form of ⟨s⟩, followed by an ⟨ʒ⟩ or ⟨s⟩, called "sharp S" or "eszett").
Diacritics

A diacritic, in some cases also called an accent, is a small symbol that can appear above or below a letter, or in some other position, such as the umlaut sign used in the German characters ⟨ä⟩, ⟨ö⟩, ⟨ü⟩ or the Romanian characters ă, â, î, ș, ț. Its main function is to change the phonetic value of the letter to which it is added, but it may also modify the pronunciation of a whole syllable or word, indicate the start of a new syllable, or distinguish between homographs such as the Dutch words een (pronounced [ən]) meaning "a" or "an", and één, (pronounced [e:n]) meaning "one". As with the pronunciation of letters, the effect of diacritics is language-dependent.
English is the only major modern European language that requires no diacritics for its native vocabulary[note 1]. Historically, in formal writing, a diaeresis was sometimes used to indicate the start of a new syllable within a sequence of letters that could otherwise be misinterpreted as being a single vowel (e.g., “coöperative”, “reëlect”), but modern writing styles either omit such marks or use a hyphen to indicate a syllable break (e.g. “cooperative”, “re-elect”). [note 2][31]
Collation
Some modified letters, such as the symbols ⟨å⟩, ⟨ä⟩, and ⟨ö⟩, may be regarded as new individual letters in themselves, and assigned a specific place in the alphabet for collation purposes, separate from that of the letter on which they are based, as is done in Swedish. In other cases, such as with ⟨ä⟩, ⟨ö⟩, ⟨ü⟩ in German, this is not done; letter-diacritic combinations being identified with their base letter. The same applies to digraphs and trigraphs. Different diacritics may be treated differently in collation within a single language. For example, in Spanish, the character ⟨ñ⟩ is considered a letter, and sorted between ⟨n⟩ and ⟨o⟩ in dictionaries, but the accented vowels ⟨á⟩, ⟨é⟩, ⟨í⟩, ⟨ó⟩, ⟨ú⟩, ⟨ü⟩ are not separated from the unaccented vowels ⟨a⟩, ⟨e⟩, ⟨i⟩, ⟨o⟩, ⟨u⟩.
Capitalization
The languages that use the Latin script today generally use capital letters to begin paragraphs and sentences and proper nouns. The rules for capitalization have changed over time, and different languages have varied in their rules for capitalization. Old English, for example, was rarely written with even proper nouns capitalized; whereas Modern English of the 18th century had frequently all nouns capitalized, in the same way that Modern German is written today, e.g. German: Alle Schwestern der alten Stadt hatten die Vögel gesehen, lit. 'All of the sisters of the old city had seen the birds'.
Romanization
Words from languages natively written with other scripts, such as Arabic or Chinese, are usually transliterated or transcribed when embedded in Latin-script text or in multilingual international communication, a process termed Romanization.
Whilst the Romanization of such languages is used mostly at unofficial levels, it has been especially prominent in computer messaging where only the limited seven-bit ASCII code is available on older systems. However, with the introduction of Unicode, Romanization is now becoming less necessary. Note that keyboards used to enter such text may still restrict users to Romanized text, as only ASCII or Latin-alphabet characters may be available.
See also
- List of languages by writing system#Latin script
- Western Latin character sets (computing)
- European Latin Unicode subset (DIN 91379)
- Latin letters used in mathematics
- Latin omega
Notes
- In formal English writing, however, diacritics are often preserved on many loanwords, such as "café", "naïve", "façade", "jalapeño" or the German prefix "über-".
- As an example, an article containing a diaeresis in "coöperate" and a cedilla in "façade" as well as a circumflex in the word "crêpe": Grafton, Anthony (23 October 2006). "Books: The Nutty Professors, The history of academic charisma". The New Yorker.
References
Citations
- Haarmann 2004, p. 96.
- "Search results | BSI Group". Bsigroup.com. Retrieved 12 May 2014.
- "Romanisation_systems". Pcgn.org.uk. Retrieved 12 May 2014.
- "ISO 15924 – Code List in English". Unicode.org. Retrieved 22 July 2013.
- "Search – ISO". Iso.org. Retrieved 12 May 2014.
- Crystal, David (2003). The Cambridge Encyclopedia of the English Language. Cambridge University Press. ISBN 9780521530330 – via Google Books.
- "Zakon O Službenoj Upotrebi Jezika I Pisama" (PDF). Ombudsman.rs. 17 May 2010. Archived from the original (PDF) on 14 July 2014. Retrieved 5 July 2014.
- "Descriptio_Moldaviae". La.wikisource.org. 1714. Retrieved 14 September 2014.
- Smith, Lahra (2013). "Review of Making Citizens in Africa: Ethnicity, Gender, and National Identity in Ethiopia". African Studies. 125 (3): 542–544. doi:10.1080/00083968.2015.1067017. S2CID 148544393 – via Taylor & Francis.
- Pütz, Martin (1997). Language Choices: Conditions, constraints, and consequences. John Benjamins Publishing. p. 216. ISBN 9789027275844.
- Gemeda, Guluma (18 June 2018). "The History and Politics of the Qubee Alphabet". Ayyaantuu. Retrieved 16 November 2021.
- Yohannes, Mekonnen (2021). "Language Policy in Ethiopia: The Interplay Between Policy and Practice in Tigray Regional State". Language Policy. 24: 33. doi:10.1007/978-3-030-63904-4. ISBN 978-3-030-63903-7. S2CID 234114762 – via Springer Link.
- Pasch, Helma (2008). "Competing scripts: The Introduction of the Roman Alphabet in Africa" (PDF). International Journal of the Sociology of Language. 191: 8 – via ResearchGate.
- Andrews, Ernest (2018). Language Planning in the Post-Communist Era: The Struggles for Language Control in the New Order in Eastern Europe, Eurasia and China. Springer. p. 132. ISBN 978-3-319-70926-0.
- Faller, Helen (2011). Nation, Language, Islam: Tatarstan's Sovereignty Movement. Central European University Press. p. 131. ISBN 978-963-9776-84-5.
- Kazakh language to be converted to Latin alphabet – MCS RK. Inform.kz (30 January 2015). Retrieved on 28 September 2015.
- "Klimkin welcomes discussion on switching to Latin alphabet in Ukraine". UNIAN (27 March 2018).
- "Moscow Bribes Bishkek to Stop Kyrgyzstan From Changing to Latin Alphabet". The Jamestown Organization (12 October 2017).
- "Kyrgyzstan: Latin (alphabet) fever takes hold". Eurasianet (13 September 2019).
- "Russian Influence in Mongolia is Declining". Global Security Review (2 March 2019). 2 March 2019.
- Tang, Didi (20 March 2020). "Mongolia abandons Soviet past by restoring alphabet". The Times. ISSN 0140-0460. Retrieved 2 March 2021.
- "Canadian Inuit Get Common Written Language". High North News (8 October 2019).
- Sands, David (12 February 2021). "Latin lives! Uzbeks prepare latest switch to Western-based alphabet". The Washington Times. Retrieved 15 February 2021.
- "Uzbekistan Aims For Full Transition To Latin-Based Alphabet By 2023". Radio Free Europe/Radio Liberty. 12 February 2021. Retrieved 15 February 2021.
- Kuzio, Taras (2007). Ukraine - Crimea - Russia: Triangle of Conflict. Columbia University Press. p. 106. ISBN 978-3-8382-5761-7.
- "Cabinet approves Crimean Tatar alphabet based on Latin letters". Ukrinform. 22 October 2021. Retrieved 17 November 2021.
- "The world's scripts and alphabets". WorldStandards. Retrieved 11 August 2020.
- "DIN 91379:2022-08: Characters and defined character sequences in Unicode for the electronic processing of names and data exchange in Europe, with CD-ROM". Beuth Verlag. Retrieved 19 August 2022.
- Koordinierungsstelle für IT-Standards (KoSIT). "String.Latin+ 1.2: eine kommentierte und erweiterte Fassung der DIN SPEC 91379. Inklusive einer umfangreichen Liste häufig gestellter Fragen. Herausgegeben von der Fachgruppe String.Latin. (zip, 1.7 MB)" [String.Latin+ 1.2: Commented and extended version of DIN SPEC 91379.] (in German). Retrieved 19 March 2022.
- "Localize Your Font: Turkish i". Glyphs. Retrieved 28 January 2021.
- "The New Yorker's odd mark — the diaeresis". 16 December 2010. Archived from the original on 16 December 2010. Retrieved 8 March 2022.
Sources
- Haarmann, Harald (2004). Geschichte der Schrift [History of Writing] (in German) (2nd ed.). München: C. H. Beck. ISBN 978-3-406-47998-4.
Further reading
- Boyle, Leonard E. 1976. "Optimist and recensionist: 'Common errors' or 'common variations.'" In Latin script and letters A.D. 400–900: Festschrift presented to Ludwig Bieler on the occasion of his 70th birthday. Edited by John J. O'Meara and Bernd Naumann, 264–74. Leiden, The Netherlands: Brill.
- Morison, Stanley. 1972. Politics and script: Aspects of authority and freedom in the development of Graeco-Latin script from the sixth century B.C. to the twentieth century A.D. Oxford: Clarendon.
External links
| Library resources about Latin script |
- Unicode collation chart—Latin letters sorted by shape
- Diacritics Project – All you need to design a font with correct accents
| Authority control: National libraries |
|---|
На других языках
[de] Lateinisches Schriftsystem
Das lateinische Schriftsystem ist ein alphabetisches Schriftsystem. Es basiert auf dem lateinischen Alphabet, das seit dem Ende seiner Entwicklung während der Renaissance 26 Buchstaben umfasst.- [en] Latin script
[ru] Латиница
Лати́ница, лати́нское письмо́ — восходящая к греческому алфавиту буквенная письменность, возникшая в латинском языке в середине I тысячелетия до н. э. и впоследствии распространившаяся по всему миру.Другой контент может иметь иную лицензию. Перед использованием материалов сайта WikiSort.org внимательно изучите правила лицензирования конкретных элементов наполнения сайта.
WikiSort.org - проект по пересортировке и дополнению контента Википедии